Sesión 4
Curso: R Aplicado a los Proyectos de Investigación
Percy Soto-Becerra, M.D., M.Sc(c)
InkaStats Data Science Solutions | Medical Branch
2022-10-10

set_var_labels() en acción
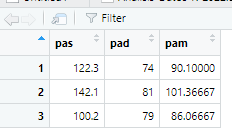
Paso 3: Identifique datos faltantes (cont.)
- Nuevamente skim() nos permite conocer, rápidamente, el número de datos perdidos.
| Name | datos |
| Number of rows | 23 |
| Number of columns | 13 |
| _______________________ | |
| Column type frequency: | |
| character | 2 |
| numeric | 11 |
| ________________________ | |
| Group variables | None |
Variable type: character
| skim_variable | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|
| tratamiento | 0 | 1 | 4 | 25 | 0 | 5 | 0 |
| protocolo | 0 | 1 | 3 | 7 | 0 | 3 | 0 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| id_jaula | 0 | 1.00 | 5.30 | 3.38 | 1.00 | 2.00 | 5.00 | 9.00 | 10.00 | ▇▃▅▂▇ |
| id_raton | 0 | 1.00 | 12.00 | 6.78 | 1.00 | 6.50 | 12.00 | 17.50 | 23.00 | ▇▆▇▆▇ |
| peso_inicial | 0 | 1.00 | 23.68 | 1.99 | 18.90 | 22.59 | 23.50 | 24.90 | 27.90 | ▂▃▇▇▂ |
| peso_final | 0 | 1.00 | 28.59 | 2.18 | 23.80 | 27.08 | 28.77 | 30.10 | 33.28 | ▂▆▇▅▂ |
| peso_utero | 0 | 1.00 | 0.09 | 0.10 | 0.01 | 0.06 | 0.07 | 0.09 | 0.54 | ▇▁▁▁▁ |
| chol | 0 | 1.00 | 81.96 | 12.89 | 59.28 | 72.31 | 82.08 | 87.29 | 107.49 | ▅▃▇▃▃ |
| glucose | 0 | 1.00 | 124.74 | 37.27 | 60.10 | 99.08 | 118.37 | 147.50 | 195.53 | ▅▇▇▃▅ |
| tag | 0 | 1.00 | 153.06 | 52.36 | 90.99 | 108.13 | 141.10 | 190.11 | 282.64 | ▇▃▅▁▂ |
| prot | 11 | 0.52 | 5.22 | 0.49 | 4.68 | 4.91 | 5.08 | 5.34 | 6.17 | ▇▃▅▁▃ |
| urea | 9 | 0.61 | 56.95 | 32.34 | 26.02 | 38.87 | 48.16 | 64.80 | 157.89 | ▇▃▁▁▁ |
| album | 12 | 0.48 | 66.15 | 8.44 | 52.77 | 62.12 | 66.82 | 69.62 | 83.73 | ▃▃▇▂▂ |
- El paquete {visdat} te permite visualizar el tipo de dato y si hay o no presencia de datos perdidos
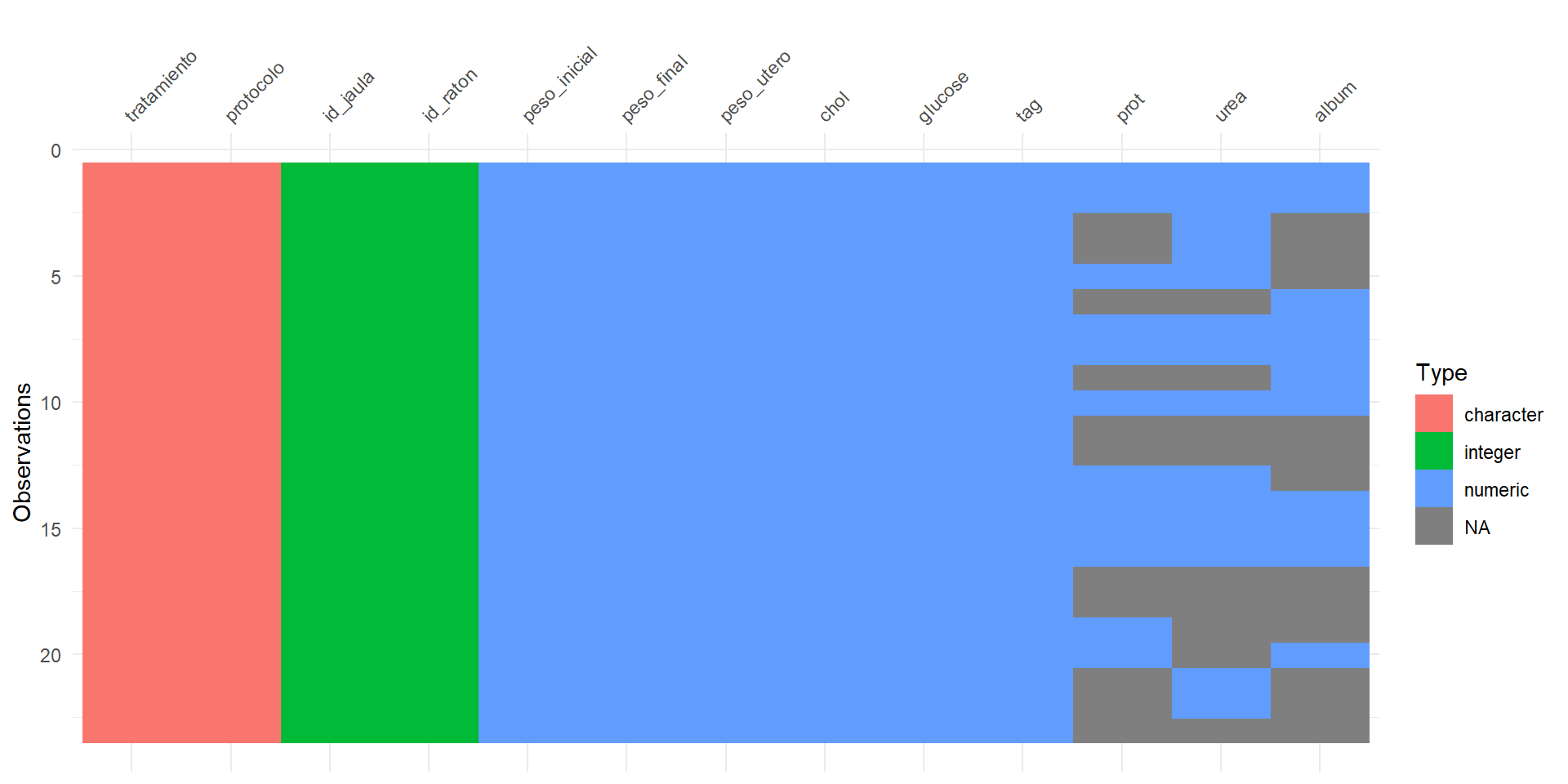
Es importante verificar si el tipo de dato corresponde con la naturaleza de la variable de estudio.
Algunos datos faltantes pueden no verse por no configurar apropiadamente el tipo de la variable.
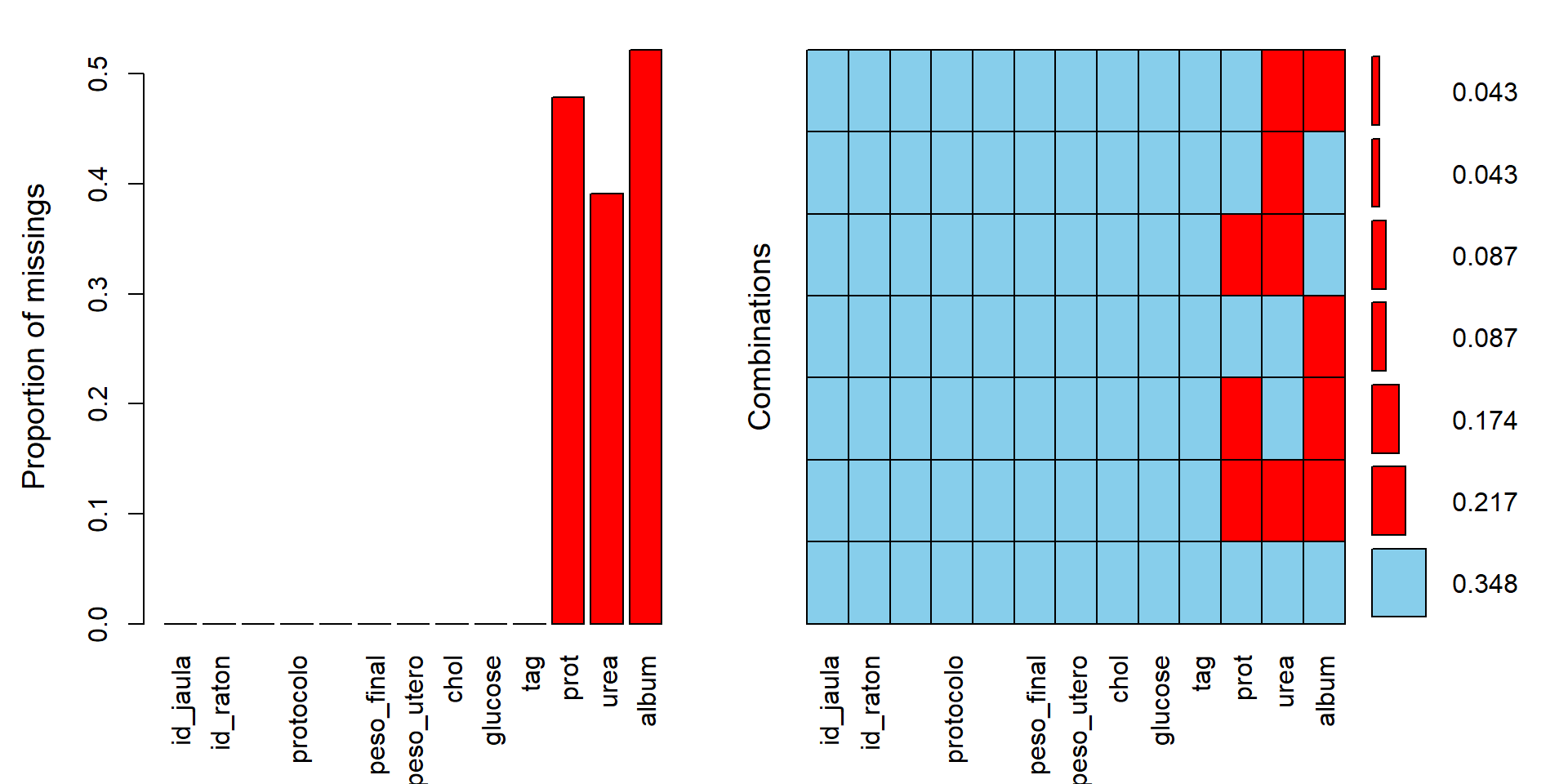
- Podemos también generar gráficos para identificar los datos perdidos y sus combinaciones:

Se aprecia que la variable
prottiene 47.83% de sus datos faltantes. La variableureatiene 39.13% de sus datos faltantes.La legenda que dice
Missing (10.7%)indica que el total de datos faltantes en las celdas (no en las filas) es de 10.7%.¿Cuántos datos faltantes en por fila tendremos? ¿Qué combinaciones de datos faltantes tendremos?
Paso 3: Identifique datos faltantes (cont.)
El paquete {VIM} permite identificar datos perdidos por variable y sus combinaciones.
Podemos visualizar los resultados directamente con la función aggr():
- También podemos usar la función gg_miss_upset del paquete {naniar} para evaluar las combinaciones de datos perdidos:
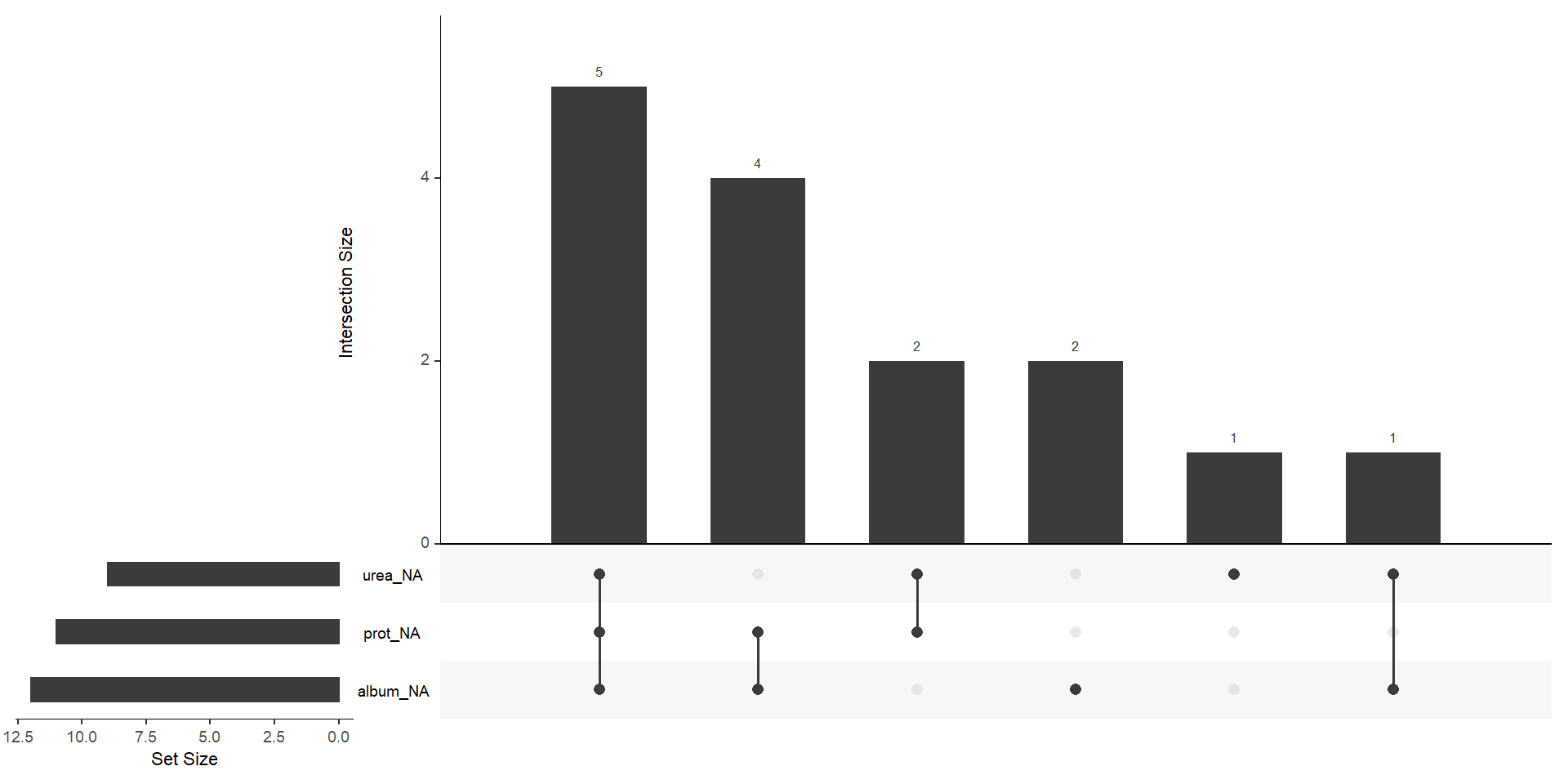
Lo primero que uno debe tratar de hacer es recuperar los datos faltantes.
Volver a revisar documentos fuentes.
Recontactar sujetos, etc.
Podemos identificar a los individuos con datos faltantes en la variable urea usando filter():
id_jaula id_raton urea
1 2 6 NA
2 3 9 NA
3 5 11 NA
4 5 12 NA
5 9 17 NA
6 9 18 NA
7 9 19 NA
8 9 20 NA
9 10 23 NASi se recupera la información, uno puede remplazar los valores usando código en R.
La función replace()del paquete {dplyr} es útil para esto. Supongamos que el dato perdido para el ratón 6 es de 65.2, podemos rempalzar el dato usando replace()
id_jaula id_raton urea
1 1 1 66.27
2 1 2 76.73
3 1 3 52.32
4 2 4 50.71
5 2 5 26.02
6 2 6 65.20
7 2 7 40.78
8 3 8 66.94
9 3 9 NA
10 3 10 34.48
11 5 11 NA
12 5 12 NA
13 5 13 37.96
14 5 14 45.61
15 8 15 38.23
16 8 16 43.06
17 9 17 NA
18 9 18 NA
19 9 19 NA
20 9 20 NA
21 10 21 60.37
22 10 22 157.89
23 10 23 NALos datos perdidos a veces se guardan por defecto con algunos caracteres especiales.
Pueden ser problemáticas si se guardan con categorías como: -99, 8888, “No aplica”, “No sabe”, etc.
Una función muy útil para lidiar con estos datos y convertirlos en
NAes la función replace_na()del paquete {tidyr}
edad diabetes
1 45 Sí
2 23 Sí
3 34 No
4 29 N/A
5 -999 No
6 23 Sí
7 34 No
8 57 N/A
9 88 N/A
10 -999 N/A
11 -999 Sí- Podemos convertir directamente todos estos valores por default a datos perdidos:
Paso 4: Identifique valores extremos no plausibles
- Revise, variable por variable
valores extremos no plausiblesoplausibles, pero sospechosamente extremos. El valor mínimo esp0y el valor máximo esp100. Deben ser plausibles.
| Name | datos |
| Number of rows | 23 |
| Number of columns | 13 |
| _______________________ | |
| Column type frequency: | |
| character | 2 |
| numeric | 11 |
| ________________________ | |
| Group variables | None |
Variable type: character
| skim_variable | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|
| tratamiento | 0 | 1 | 4 | 25 | 0 | 5 | 0 |
| protocolo | 0 | 1 | 3 | 7 | 0 | 3 | 0 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| id_jaula | 0 | 1.00 | 5.30 | 3.38 | 1.00 | 2.00 | 5.00 | 9.00 | 10.00 | ▇▃▅▂▇ |
| id_raton | 0 | 1.00 | 12.00 | 6.78 | 1.00 | 6.50 | 12.00 | 17.50 | 23.00 | ▇▆▇▆▇ |
| peso_inicial | 0 | 1.00 | 23.68 | 1.99 | 18.90 | 22.59 | 23.50 | 24.90 | 27.90 | ▂▃▇▇▂ |
| peso_final | 0 | 1.00 | 28.59 | 2.18 | 23.80 | 27.08 | 28.77 | 30.10 | 33.28 | ▂▆▇▅▂ |
| peso_utero | 0 | 1.00 | 0.09 | 0.10 | 0.01 | 0.06 | 0.07 | 0.09 | 0.54 | ▇▁▁▁▁ |
| chol | 0 | 1.00 | 81.96 | 12.89 | 59.28 | 72.31 | 82.08 | 87.29 | 107.49 | ▅▃▇▃▃ |
| glucose | 0 | 1.00 | 124.74 | 37.27 | 60.10 | 99.08 | 118.37 | 147.50 | 195.53 | ▅▇▇▃▅ |
| tag | 0 | 1.00 | 153.06 | 52.36 | 90.99 | 108.13 | 141.10 | 190.11 | 282.64 | ▇▃▅▁▂ |
| prot | 11 | 0.52 | 5.22 | 0.49 | 4.68 | 4.91 | 5.08 | 5.34 | 6.17 | ▇▃▅▁▃ |
| urea | 9 | 0.61 | 56.95 | 32.34 | 26.02 | 38.87 | 48.16 | 64.80 | 157.89 | ▇▃▁▁▁ |
| album | 12 | 0.48 | 66.15 | 8.44 | 52.77 | 62.12 | 66.82 | 69.62 | 83.73 | ▃▃▇▂▂ |
- Permite hacer algo similar
datos
13 Variables 23 Observations
--------------------------------------------------------------------------------
id_jaula
n missing distinct Info Mean Gmd
23 0 7 0.979 5.304 3.881
lowest : 1 2 3 5 8, highest: 3 5 8 9 10
Value 1 2 3 5 8 9 10
Frequency 3 4 3 4 2 4 3
Proportion 0.130 0.174 0.130 0.174 0.087 0.174 0.130
--------------------------------------------------------------------------------
id_raton
n missing distinct Info Mean Gmd .05 .10
23 0 23 1 12 8 2.1 3.2
.25 .50 .75 .90 .95
6.5 12.0 17.5 20.8 21.9
lowest : 1 2 3 4 5, highest: 19 20 21 22 23
--------------------------------------------------------------------------------
tratamiento
n missing distinct
23 0 5
lowest : control maca maca + critro sham operated triple dosis maca + citro
highest: control maca maca + critro sham operated triple dosis maca + citro
control (5, 0.217), maca (5, 0.217), maca + critro (4, 0.174), sham operated
(4, 0.174), triple dosis maca + citro (5, 0.217)
--------------------------------------------------------------------------------
protocolo
n missing distinct
23 0 3
Value hemiovx no ovx ovx
Frequency 2 4 17
Proportion 0.087 0.174 0.739
--------------------------------------------------------------------------------
peso_inicial
n missing distinct Info Mean Gmd .05 .10
23 0 19 0.998 23.68 2.244 20.55 21.90
.25 .50 .75 .90 .95
22.59 23.50 24.90 25.90 26.53
lowest : 18.90 20.40 21.90 22.40 22.50, highest: 25.30 25.50 26.00 26.59 27.90
Value 18.90 20.40 21.90 22.40 22.50 22.69 22.90 23.20 23.40 23.50 23.90
Frequency 1 1 2 1 1 1 1 1 2 2 1
Proportion 0.043 0.043 0.087 0.043 0.043 0.043 0.043 0.043 0.087 0.087 0.043
Value 24.50 24.80 25.00 25.30 25.50 26.00 26.59 27.90
Frequency 2 1 1 1 1 1 1 1
Proportion 0.087 0.043 0.043 0.043 0.043 0.043 0.043 0.043
--------------------------------------------------------------------------------
peso_final
n missing distinct Info Mean Gmd .05 .10
23 0 21 0.999 28.59 2.483 25.11 26.68
.25 .50 .75 .90 .95
27.08 28.77 30.10 30.49 32.02
lowest : 23.80 24.93 26.68 26.70 26.86, highest: 30.37 30.43 30.50 32.19 33.28
--------------------------------------------------------------------------------
peso_utero
n missing distinct Info Mean Gmd .05 .10
23 0 23 1 0.0927 0.07728 0.0166 0.0268
.25 .50 .75 .90 .95
0.0560 0.0680 0.0885 0.1298 0.1718
lowest : 0.014 0.016 0.022 0.046 0.052, highest: 0.108 0.113 0.134 0.176 0.535
--------------------------------------------------------------------------------
chol
n missing distinct Info Mean Gmd .05 .10
23 0 21 0.999 81.96 14.9 64.54 66.05
.25 .50 .75 .90 .95
72.31 82.08 87.29 98.89 104.36
lowest : 59.28 64.40 65.79 67.10 68.40, highest: 94.46 95.76 99.67 104.88 107.49
--------------------------------------------------------------------------------
glucose
n missing distinct Info Mean Gmd .05 .10
23 0 23 1 124.7 43.44 72.54 78.90
.25 .50 .75 .90 .95
99.08 118.37 147.50 179.63 184.30
lowest : 60.10 71.91 78.22 81.62 94.23, highest: 160.36 168.50 182.41 184.51 195.53
--------------------------------------------------------------------------------
tag
n missing distinct Info Mean Gmd .05 .10
23 0 22 1 153.1 59.41 93.45 96.35
.25 .50 .75 .90 .95
108.13 141.10 190.11 209.50 241.54
lowest : 90.99 93.19 95.82 98.46 105.49, highest: 199.12 200.00 211.87 244.84 282.64
--------------------------------------------------------------------------------
prot
n missing distinct Info Mean Gmd .05 .10
12 11 10 0.993 5.222 0.5367 4.735 4.787
.25 .50 .75 .90 .95
4.910 5.085 5.340 6.045 6.143
lowest : 4.68 4.78 4.85 4.93 5.02, highest: 5.15 5.33 5.37 6.12 6.17
Value 4.68 4.78 4.85 4.93 5.02 5.15 5.33 5.37 6.12 6.17
Frequency 1 1 1 2 1 1 2 1 1 1
Proportion 0.083 0.083 0.083 0.167 0.083 0.083 0.167 0.083 0.083 0.083
--------------------------------------------------------------------------------
urea
n missing distinct Info Mean Gmd .05 .10
14 9 14 1 56.95 30.41 31.52 35.52
.25 .50 .75 .90 .95
38.87 48.16 64.80 73.79 105.14
lowest : 26.02 34.48 37.96 38.23 40.78, highest: 60.37 66.27 66.94 76.73 157.89
Value 26.02 34.48 37.96 38.23 40.78 43.06 45.61 50.71 52.32
Frequency 1 1 1 1 1 1 1 1 1
Proportion 0.071 0.071 0.071 0.071 0.071 0.071 0.071 0.071 0.071
Value 60.37 66.27 66.94 76.73 157.89
Frequency 1 1 1 1 1
Proportion 0.071 0.071 0.071 0.071 0.071
--------------------------------------------------------------------------------
album
n missing distinct Info Mean Gmd .05 .10
11 12 11 1 66.15 9.592 54.06 55.36
.25 .50 .75 .90 .95
62.12 66.82 69.62 72.14 77.94
lowest : 52.77 55.36 59.59 64.64 66.27, highest: 67.09 68.59 70.64 72.14 83.73
Value 52.77 55.36 59.59 64.64 66.27 66.82 67.09 68.59 70.64 72.14 83.73
Frequency 1 1 1 1 1 1 1 1 1 1 1
Proportion 0.091 0.091 0.091 0.091 0.091 0.091 0.091 0.091 0.091 0.091 0.091
--------------------------------------------------------------------------------El
gráfico de cajasnos muestra la disrtibución de la variable numérica en termino de sus cuantiles.Los
puntos aislados, fuera de las cajas y bigotes, son considerados valores extremos.Estos pueden ser
plausiblesono plausibles.El gráfico de cajas permite
identificar, rápidamente,valores extremospotencialmenteno plausiblesoproblemáticos.
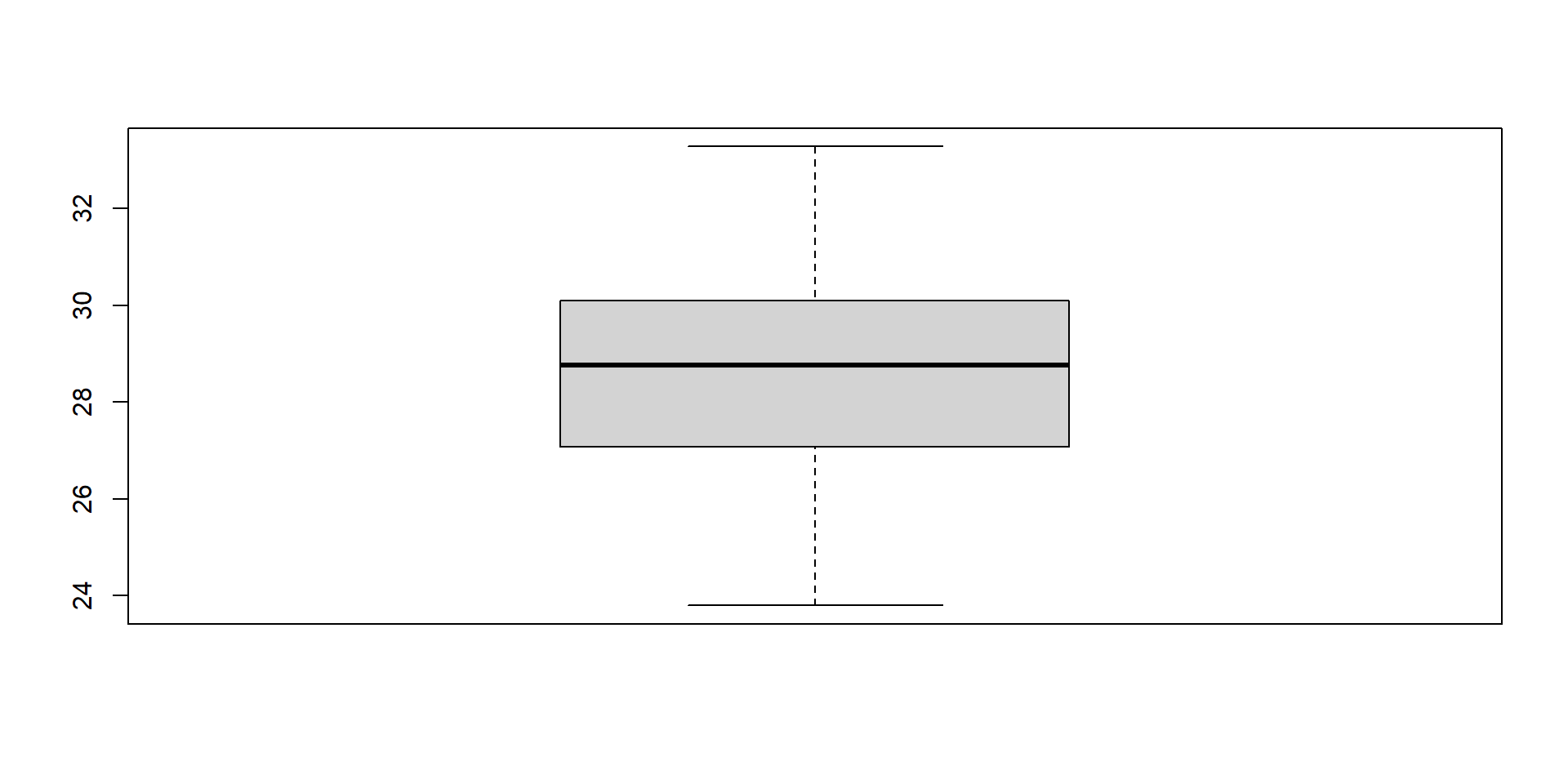
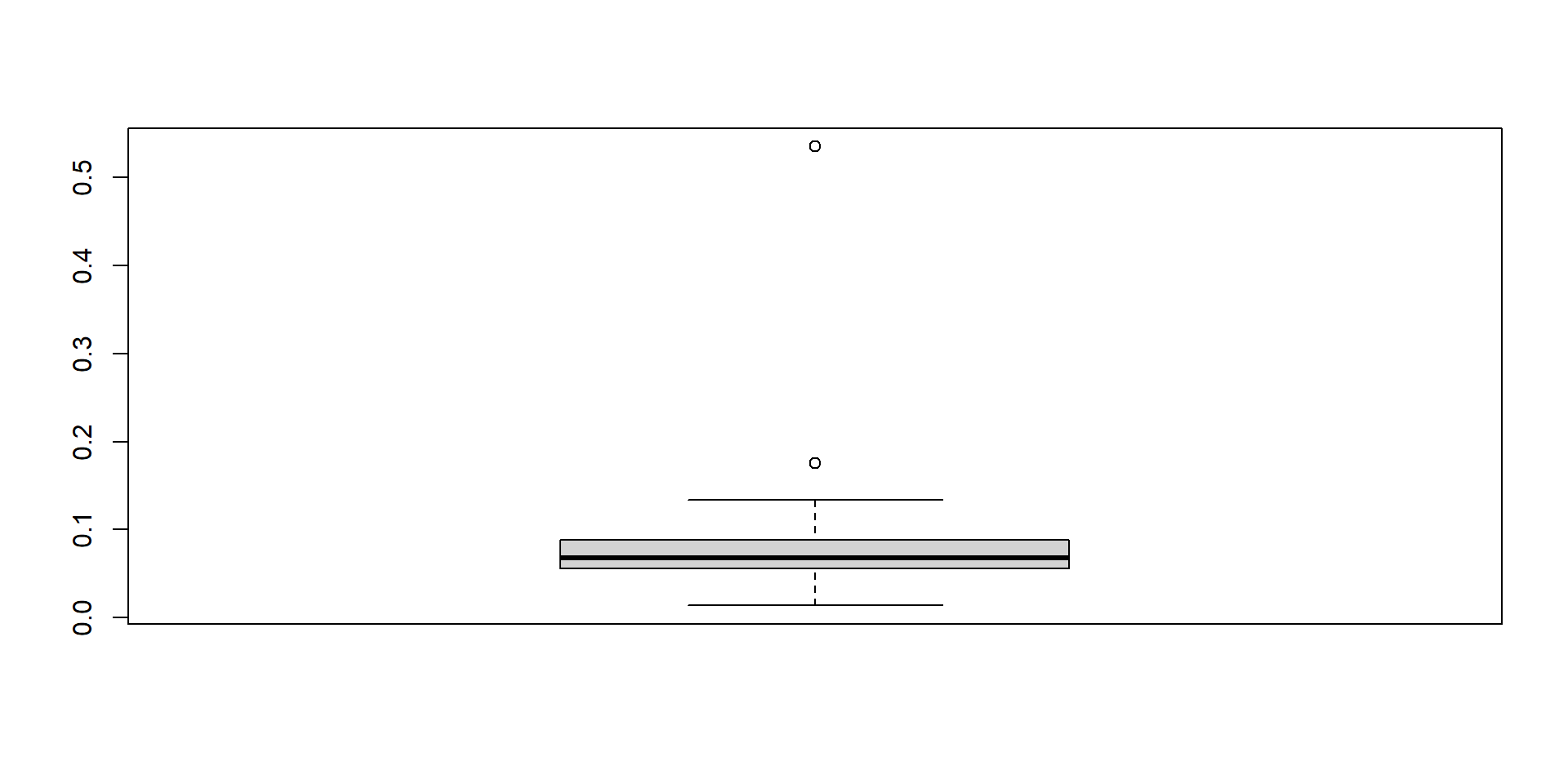
Los datos extremos pueden ser valores anómalos válidos.
En ocasiones, son valores no plausibles, inválidos, producto del mal recojo de información.
Cuando se tenga valores extremos no plausibles se puede optar por dos acciones:
- Corregir el valor extremo no plausible por datos que sí sean plausibles.
- Si no se puede, convertir los valores extremos no plausibles en datos faltantes (veremos esto).
- Bonus: A veces puede ser mejor recortar los datos y quedarse con el 1% y 99% percentil más bajo y alto, respectivamente.
@psotob91
https://github.com/psotob91
percys1991@gmail.com