Sesión 5
Curso: R Aplicado a los Proyectos de Investigación
Percy Soto-Becerra, M.D., M.Sc(c)
InkaStats Data Science Solutions | Medical Branch
2022-10-12

Análisis descriptivo de variable numérica
- Medias de tendencia central
- Media
- Mediana (es también
medida de posición) - Moda (no es usual)
- Medidas de posición
- Cuantiles (en general)
- Mediana = percentil 50 (es también medida de
tendencia central) - Percentil 25 (p25)
- Percentil 75 (p75)
- Medidas de dispersión
- Rango (máximo - mínimo)
- Varianza / Desviación estándar
- Rango intercuartílico (p75 - p25)
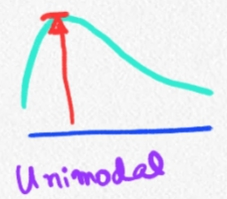
- De acuerdo a moda:
- Unimodal (una sola moda)
- Multimodal (p. ej, bimodal)
- Uniforme (no moda)
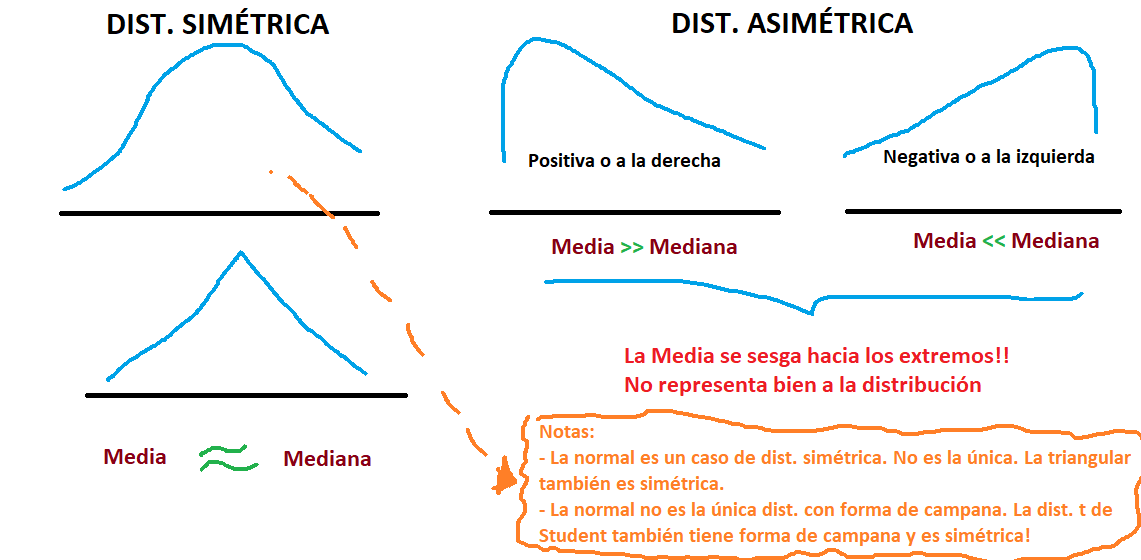
- De acuerdo a simetría
- Simétrica
- Asimétrica (o ‘sesgada’)
- Positiva (A la derecha)
- Negativa (A la izquierda)
- De acuerdo a curtosis:
- Leptocúrtica
- Mesocúrtica
- Platicúrtica
Medidas de resumen: Tendencia central
- La media artimética de una lista de números, es la suma de estos números dividida por la cantidad de esto y está dada por la siguiente expresión:
\[\bar{x} = \frac{x_1 + x_2 + x_3 + ... + x_n}{n} = \frac{\sum_{i = 1}^{n}x_i}{n}\]
Ejemplo
Sean las siguientes edades en años: \(36, 4, 75, 45, 50\), su media aritmética es
\[\frac{36 + 4 + 75 + 45 + 50}{5} = \frac{210}{5} = 42\]
Forma de promedio útil para conjuntos de números positivos que se desean interpretar de acuerdo a su producto en vez de su suma.
Es la raíz \(n-ésima\) del producto de los números y está dada por la siguiente expresión:
\[\bar{x}_{g} = \sqrt[n]{x_1x_2x_3...x_n} = (x_1x_2x_3...x_n)^{\frac{1}{n}} = (\prod_{i = 1}^{n}x_i)^{\frac{1}{n}}\]
Ejemplo
Sean las siguientes edades en años: \(36, 4, 75, 45, 50\), su media geométrica es
\[(36 \times 4 \times 75 \times 45 \times 50) ^ {\frac{1}{5}} = \sqrt[5]{24300000} = 30\]
Media truncada
Media truncada o recortada (en inglés trimmed mean) es una medida de tendencia central similar a la media aritmética que se calcula luego de descartar las partes de ambos extremos de la distribución.
Típicamente se descartan las mismas proporcions de datos en los extremos.
En la mayoría de aplicaciones se descartan entre 5% a 25%.
En algunas regiones también la conocen como media windsoriana.
La usan mucho en eventos de competición para eliminar la influencia de las calificaciones extremas de los jueces
Media armónica
Es un tipo de medida promedio conocida por ser una de las medias pitagóricas.
Se expresa como el recíproco de las medias aritméticas de los recíprocos de un conjunto dado de observaciones.
\[H = \frac{n}{\frac{1}{x_1} + \frac{1}{x_2} + ... + \frac{1}{x_n}} = \frac{n}{\sum_{i=1}^{n}{\frac{1}{x_i}}} = (\frac{\sum_{i=1}^{n}x_i^{-1}}{n})^{-1} \] - Es más útil en situaciones donde se desea promediar tasas o estadístico similares basados en medidas de razón.
- Sean \(x_{(1)}, x_{(2)}, x_{(3)}, ..., x_{(i)},..., x_{(n)}\) estadísticos de orden, es decir cada \(x_{(i)}\) representa al \(i-ésimo\) valor más pequeño de la muestra, entonces la mediana está dada por la siguiente expresión:
\[ Med(x) = \begin{cases} x_{(n+1)/2} & \text{si n es impar} \\ \frac{x_{(n/2)}+x_{(n/2+1)}}{2} & \text{si n es par} \end{cases} \]
Ejemplo
Luego de ordenar de menor a mayor, tenemos \(4, 36, 45, 50, 75\). Como \(n = 5\) es impar, entonces
\[Med(x) = x_{(5+1)/2} = x_{(3)} = 45\]
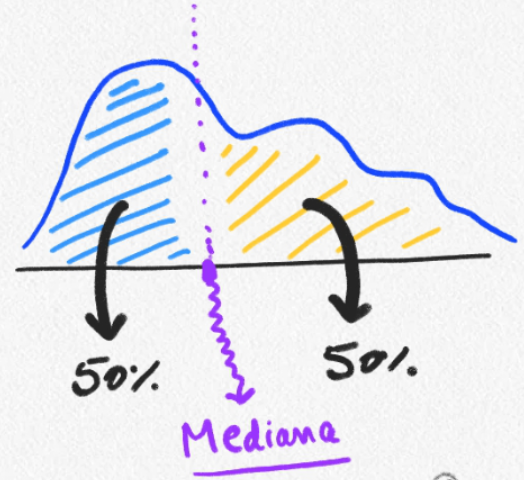
- En otras palabras, es el valor que separa la mitad superior de la mitad inferior de una muestra de datos.
Es el valor que aparece más frecuentemente en los datos.
- De poca utilidad en variables numéricas.
No necesariamente es única.
Unimodal
Multimodal
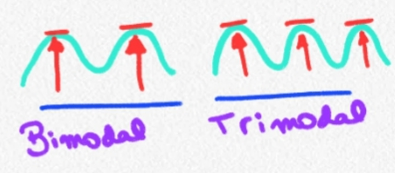
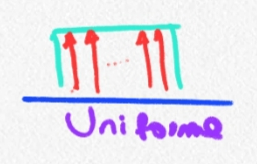
Multimodal extremo: Uniforme
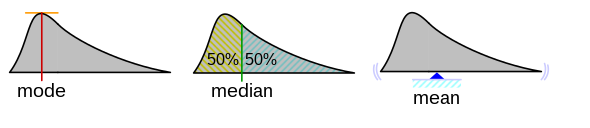
En resumen, la visualización geométrica de la media, mediana y moda para una distribución unimodal es la siguiente.
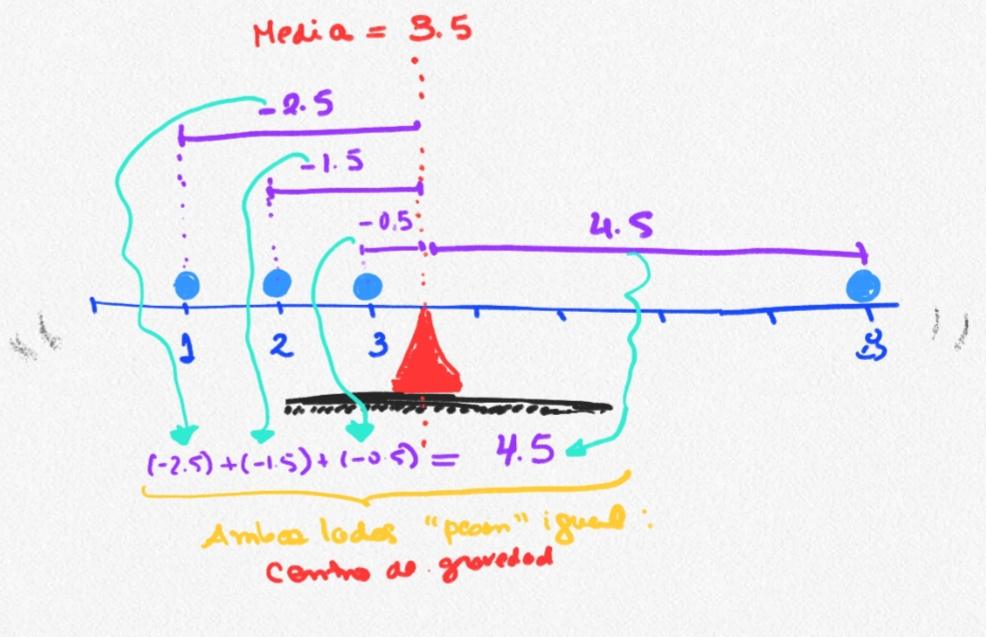
Moda:Valor más frecuente (punta más alta de distribución)Mediana:Valor que divide datos en 50% (mitad de la distribución)Media:Centro de gravedad (punto en el que los “pesos” de ambos lados se igualan)
Funciones
Funciones de R base:
mean()
mean(…, trim = …)
median()
Funciones extras a R base:
- geometric.mean() de {psych}
Datos para los cálculos
- Sean el vector de edades:
- Sea el vector de hemoglobina:
Media aritmética
- En vector con datos completos:
- En vector con datos incompletos:
- Es necesario agregar na.rm = TRUE
Media geométrica
- Manualemente
- Con librería psych
Media truncada
- Solo 5% de ambas colas
Mediana
Medidas de resumen: Posición
Son los valores que funcionana como puntos de corte para dividir el rango de datos en intervalos continuos con igual frecuencia.
El \(k-ésimo\) \(q-cuantil\) es el valor de los datos donde su función de distribución acumulada cruza \(k/q\).
Es decir, \(x\) es el \(k-ésimo\) \(q-cuantil\) para una variable \(X\) si:
\[Pr[X < x] \leq k/q\]
\[Pr[X \leq x] \geq k/q \]
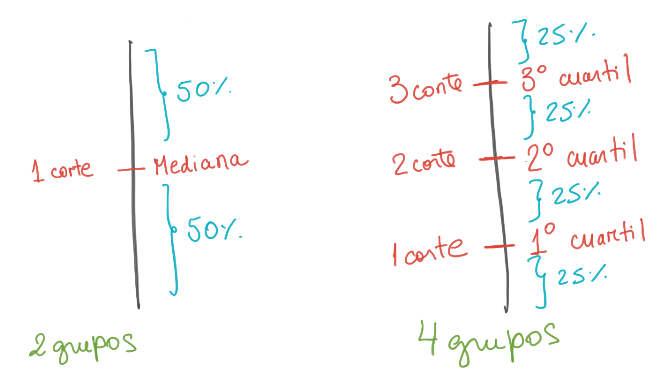
El nombre del cuantil depende de cuántos grupos se forman.
La cantidad de cuantiles es siempre 1 menos.
- Ejemplo, para formar 4 grupos, necesito solo 3 cortes: 3 cuartiles
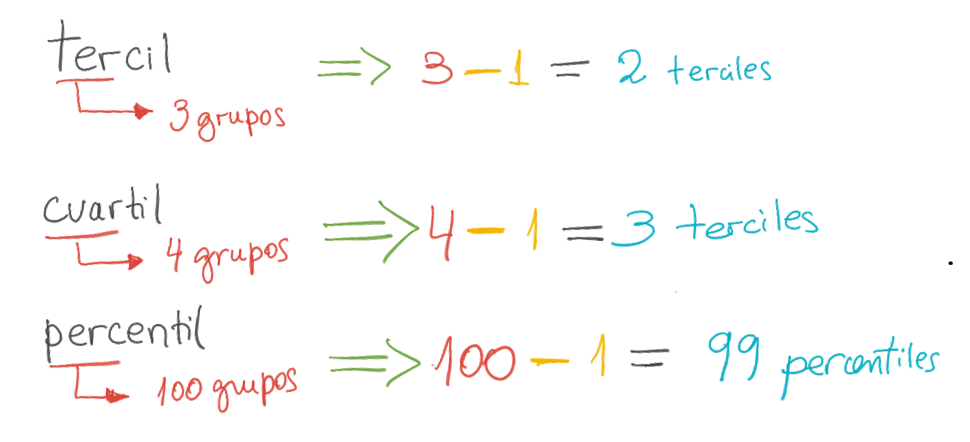
Hay una lista bastante grande de cuantiles.
Los más famosos son:
- Mediana
- Terciles
- Cuartiles
- Quintiles
- Deciles
- Percentiles.
| Q-cuantil | Nombre del cuantil | Número de grupos iguales | Número de cuantiles |
|---|---|---|---|
| 2-cuantil | Mediana | 2 | 1 |
| 3-cuantil | Terciles | 3 | 2 |
| 4-cuantil | Cuartiles | 4 | 3 |
| 5-cuantil | Quintiles | 5 | 4 |
| 6-cuantil | Sextiles | 6 | 5 |
| 7-cuantil | Septiles | 7 | 6 |
| 8-cuantil | Octiles | 8 | 7 |
| 10-cuantil | Deciles | 10 | 9 |
| 12-cuantil | Dodeciles | 12 | 11 |
| 16-cuantil | Hexadeciles | 16 | 15 |
| 20-cuantil | Ventiles | 20 | 19 |
| 100-cuantil | Percentiles | 100 | 99 |
| 1000-cuantil | Permiles o Mililes | 1000 | 999 |
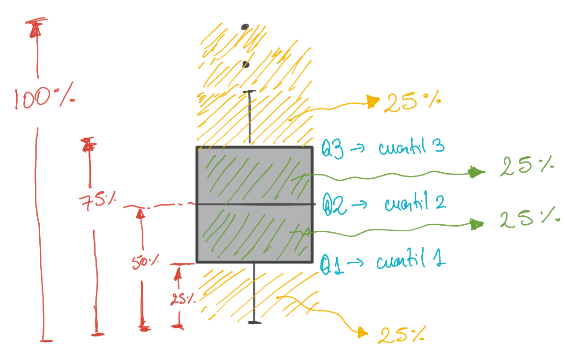
Los cuartiles dividen los datos en cuatro partes iguales
- Por lo tanto, hay 3 cuartiles.
Los gráficos de cajas utilizan los cuartiles para realizar el dibujo de los elementos de la caja.
- El segundo cuartil es equivalente a la mediana porque contiene el 50% de los datos.
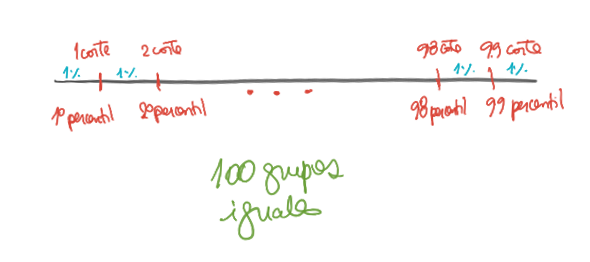
Los percentiles dividen los datos en 100 partes iguales
- Por lo tanto, son 99 percentiles.
Se usan para construir infinidad de estadísticos:
- Tablas de crecimiento, ranking de calificaciones, etc.
En inferencia estadística, se usan para establecer
- Nivel de confianza
- Nivel de significancia.
Funciones
Funciones de R base:
- quantile(…, probs = …)
Datos para los cálculos
- Sean el vector de edades:
- Sea el vector de hemoglobina:
Cuartiles
- Cuartil 1 (25%)
- Cuartil 3 (75%)
- Cuartiles 1, 2 y 3
Percentiles
- Percentil 67
- Percentiles del 1 al 99
0% 1% 2% 3% 4% 5% 6% 7% 8% 9% 10% 11% 12%
6.00 6.05 6.10 6.15 6.20 6.25 6.30 6.35 6.40 6.45 6.50 6.55 6.60
13% 14% 15% 16% 17% 18% 19% 20% 21% 22% 23% 24% 25%
6.65 6.70 6.75 6.80 6.85 6.90 6.95 7.00 7.05 7.10 7.15 7.20 7.25
26% 27% 28% 29% 30% 31% 32% 33% 34% 35% 36% 37% 38%
7.30 7.35 7.40 7.45 7.50 7.55 7.60 7.65 7.70 7.75 7.80 7.85 7.90
39% 40% 41% 42% 43% 44% 45% 46% 47% 48% 49% 50% 51%
7.95 8.00 8.05 8.10 8.15 8.20 8.25 8.30 8.35 8.40 8.45 8.50 8.55
52% 53% 54% 55% 56% 57% 58% 59% 60% 61% 62% 63% 64%
8.60 8.65 8.70 8.75 8.80 8.85 8.90 8.95 9.00 9.05 9.10 9.15 9.20
65% 66% 67% 68% 69% 70% 71% 72% 73% 74% 75% 76% 77%
9.25 9.30 9.35 9.40 9.45 9.50 9.55 9.60 9.65 9.70 9.75 9.80 9.85
78% 79% 80% 81% 82% 83% 84% 85% 86% 87% 88% 89% 90%
9.90 9.95 10.00 10.10 10.20 10.30 10.40 10.50 10.60 10.70 10.80 10.90 11.00
91% 92% 93% 94% 95% 96% 97% 98% 99%
11.10 11.20 11.30 11.40 11.50 11.60 11.70 11.80 11.90 Frecuencias Relativas en Bioestadística y Epi Clínica
Proporción de una población específica que está afectada por un evento de salud de interés (típicamente una enfermedad o factor de riesgo, pero también puede ser factor benéfico) en un tiempo específico.
\[Prevalencia = \frac{\text{Nº de eventos en t}}{\text{Nº de eventos + Nº sin evento en t}}\]
El tiempo específico puede ser un punto, un periodo o toda una vida.
Puede calcularse en una muestra cualquiera, pero a menudo interesan prevalencias de poblaciones relevantes.
- Hablaremos de esto mejor en la sección de estimación.
- Tipos de prevalencia: Dependen de qué es \(t\)
- Prevalencia puntual: \(t\) es solo un momento.
- Prevalencia de intervalo: \(t\) es un intervalo definido de tiempo.
- Prevalencia de vida: \(t\) es todo el intervalo de la vida del sujeto (desde que ocurrió alguna vez el evento).
Proporción de incidencia o incidencia acumulada es la probabilidad de que ocurra un nuevo evento particular (tal como una enfermedad) antes de un tiempo dado.
- El cáculo es directo si no han habido pérdidas en el seguimiento de los individuos y la fórmula es la siguiente:
\[ \text{Incidencia Acumulada} = \frac{\text{Nº eventos nuevos durante periodo t}}{\text{Nº de individuos sin evento en risgo al inicio del periodo t}} \]
- El cálculo no es directo si hay pérdidas de seguimiento (lo conversaremos en otra clase).
Prevalencia versus Incidencia Acumulada
| Prevalencia | Incidencia Acumulada | |
|---|---|---|
| Numerador | Eventos existentes en t | Eventos nuevos durante el periodo t |
| Denominador | Todos los individuos (con y sin eventos) en t | Individuos sin evento al inicio del periodo t |
| ¿Probabilidad de qué...? | Probabilidad de tener el evento | Probabilidad de desarrolalr evento nuevo |
| Notas | Solo requiere un punto en el tiempo. A menudo se busca poblaciones relevantes y usa muestras probabilísticas. | Requiere al menos dos puntos de tiempo. Puede estimarse en poblaciones relevantes. A menudo se usan muestras no probabilísticas en las que es factible el seguimiento (p. ej., pacientes) |
Es la razón de la probabilidad del evento entre la probabilidad del no evento.
\[Odds = \frac{Pr(evento)}{Pr(\text{no evento})} = \frac{Pr(evento)}{1 - Pr(\text{evento})}\]
Es solo una forma diferente de escribir la probabilidad del evento.
- Análogo a expresar en céntimos y no en soles el precio de algo.
- Por tanto, es una forma diferente de expresar lo mismo:
- La frecuencia relativa de un evento y, a través de esta, su incertidumbre asociada.
- Si probabilidad de ganar es de 0.8 (~80%), entonces el odds es 4. El odds se interpretaría como:
La probabilidad de ganar es 4
veces la probabilidad de perder.
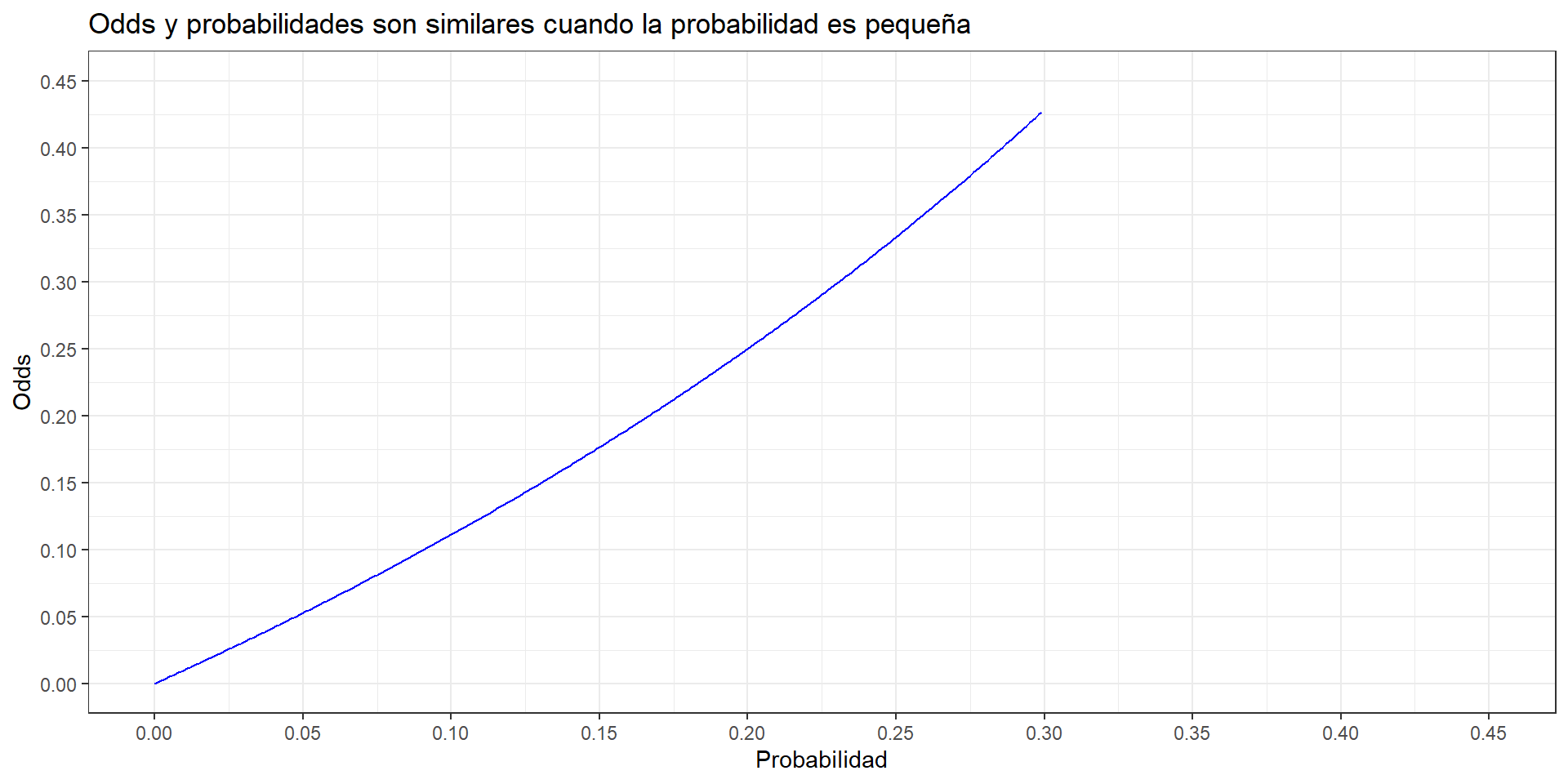
- Odds y probabilidad son diferentes, pero tienen valores muy similares cuando la probabilidad del evento es muy pequeña.
| Probabilidad | Odds | Diferencia |
|---|---|---|
| 0.000 | 0.0000000 | 0.0000000 |
| 0.010 | 0.0101010 | 0.0001010 |
| 0.020 | 0.0204082 | 0.0004082 |
| 0.030 | 0.0309278 | 0.0009278 |
| 0.040 | 0.0416667 | 0.0016667 |
| 0.050 | 0.0526316 | 0.0026316 |
| 0.100 | 0.1111111 | 0.0111111 |
| 0.200 | 0.2500000 | 0.0500000 |
| 0.300 | 0.4285714 | 0.1285714 |
| 0.400 | 0.6666667 | 0.2666667 |
| 0.500 | 1.0000000 | 0.5000000 |
| 0.800 | 4.0000000 | 3.2000000 |
| 0.900 | 9.0000000 | 8.1000000 |
| 0.990 | 99.0000000 | 98.0100000 |
| 0.999 | 999.0000000 | 998.0010000 |
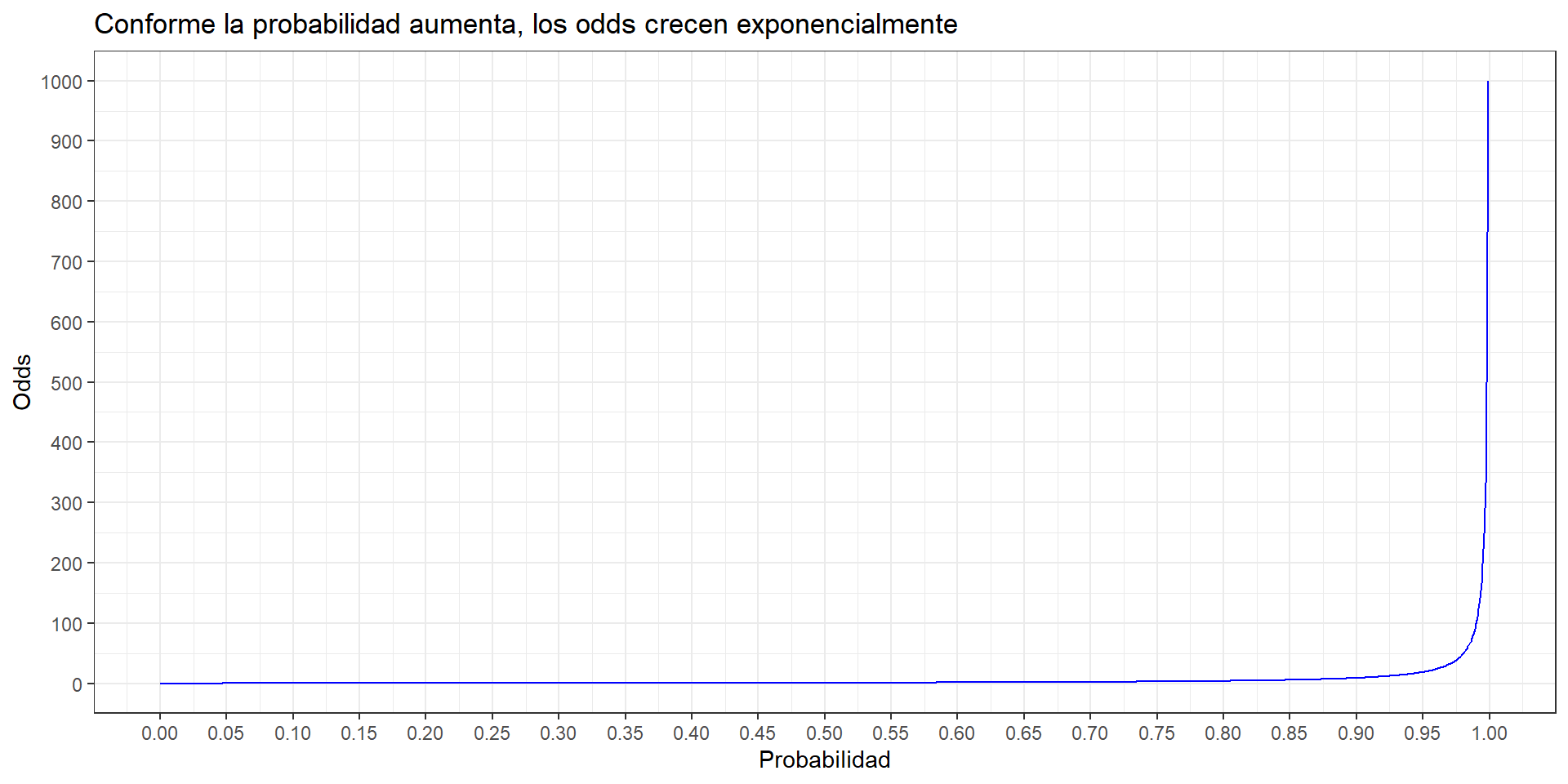
Los odds no se usan mucho en epidemiología para expresar frecuencias; pero una medida derivada de esta sí se usa mucho para expresar asociación: la razón de odds (OR).
En epidemiología, las proporciones o probabilidades puede ser incidencias acumuladas o prevalencias, por lo que tenemos dos tipos de Odds:
\[Odds_{Prevalente} = \frac{Prevalencia}{1 - Prevalencia}\]
\[Odds_{Incidente} = \frac{\text{Incidencia Acumulada}}{1 - \text{Incidencia Acumulada}}\]
Tabla decriptiva reproducible con {gtsummary}
Permite crear tablas en formato de revistas biomédicas.
Función tbl_summary() para tablas descriptivas univariadas y comparativas (bivariadas)
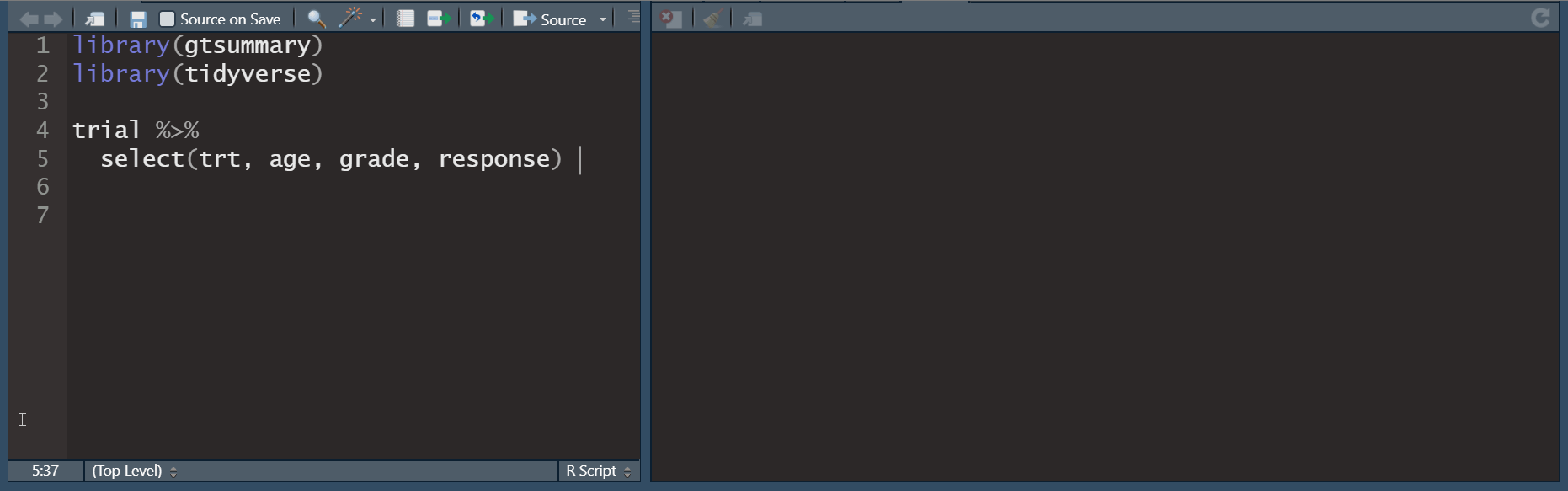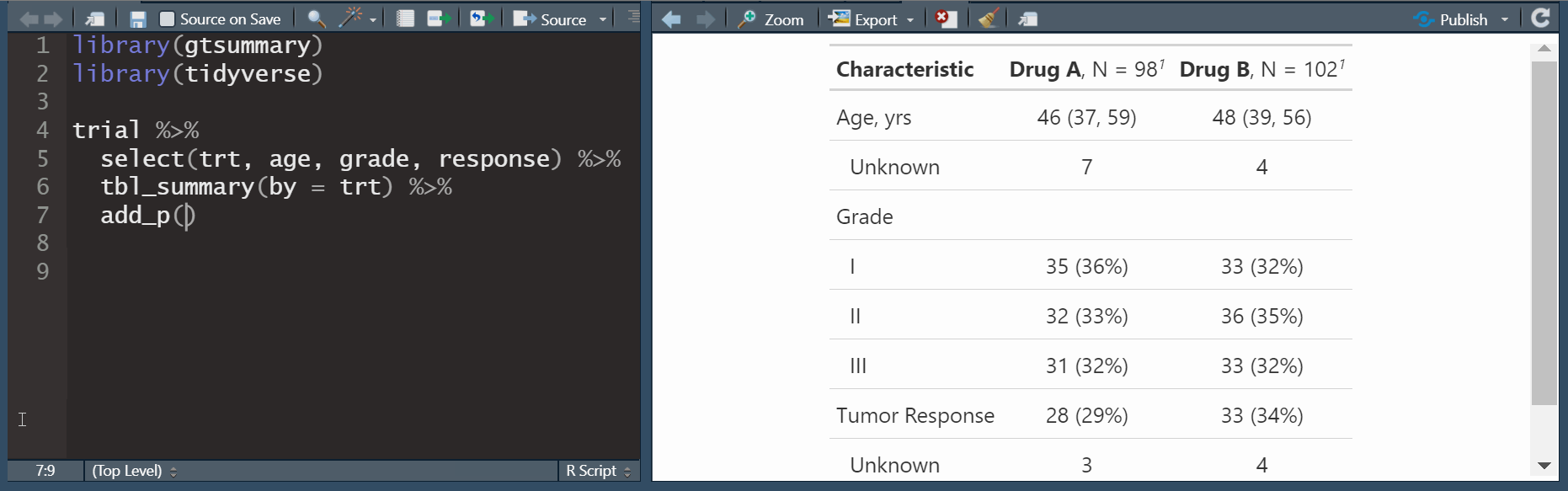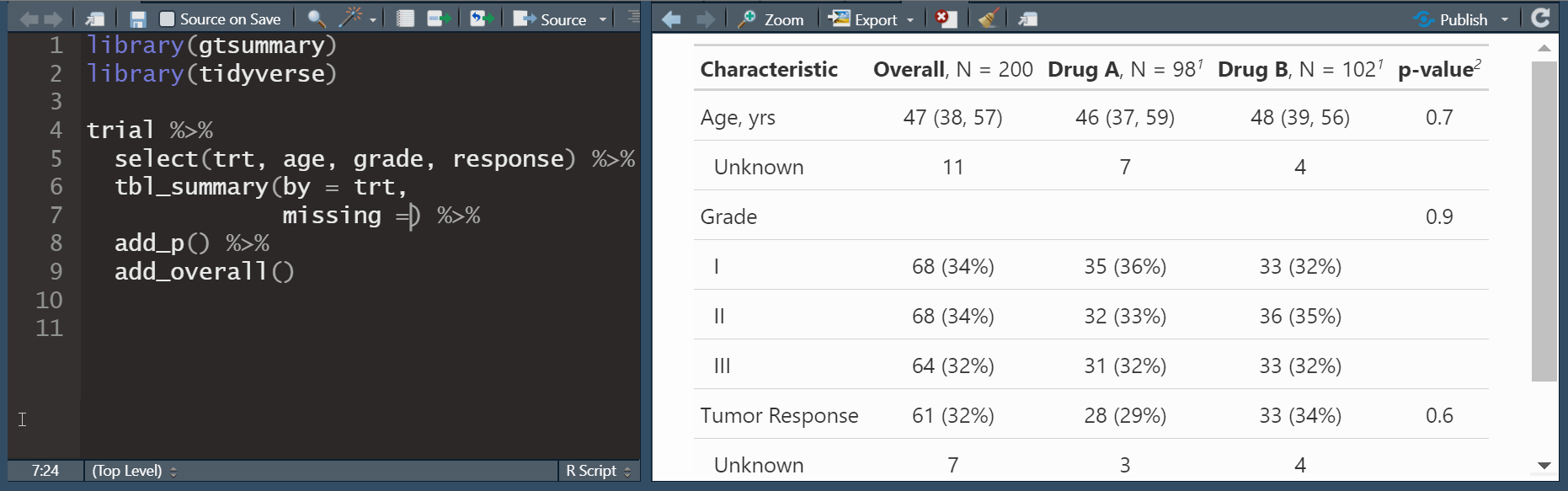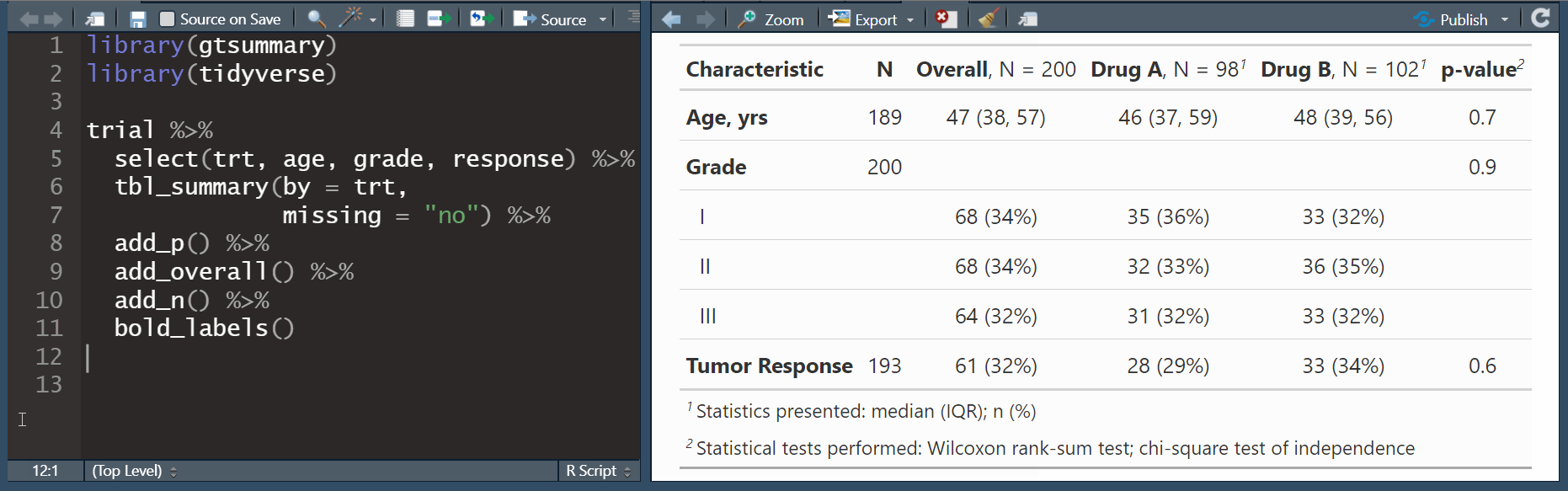
tbl_summary() básico
- Seleccionar las variables que desea reportar con función select(), luego usar tbl_summary():
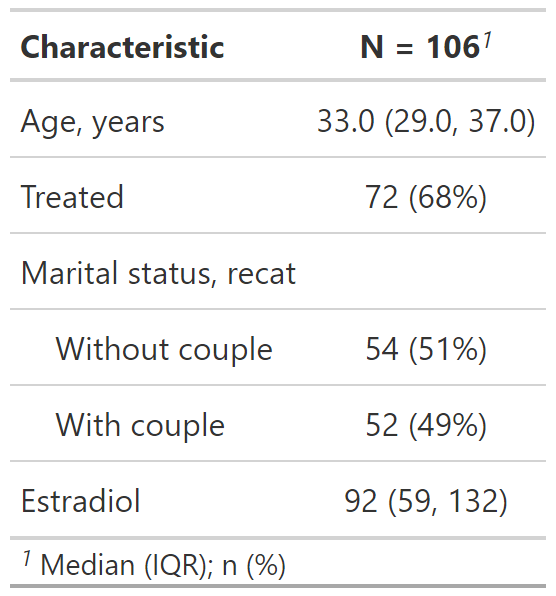
Cuarto tipo de resumenes: continuous, continuos2, categorical y dichotomous
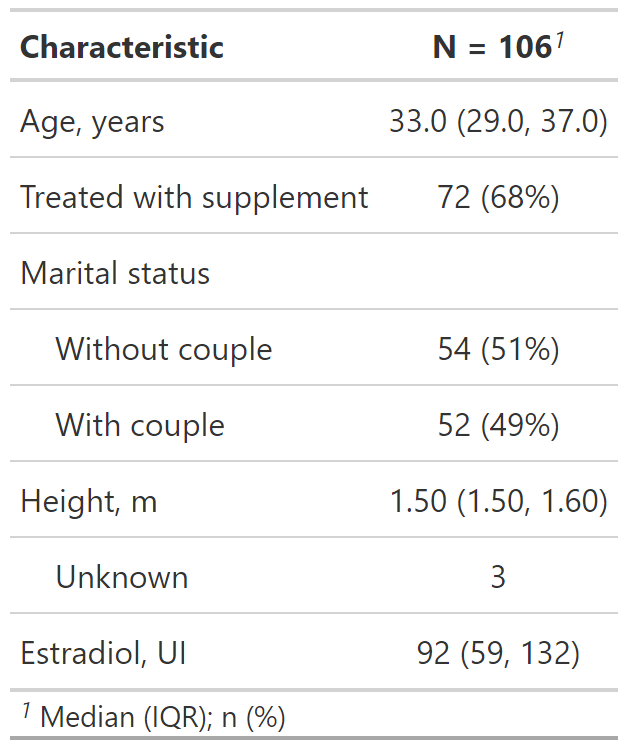
Por defecto, los estadísticos son reportadas como mediana (percentil 25, percentil 75) para variables numéricas y n (%) para variables categóricas/dicotómicas.
Las variables codificadas como 0 / 1, TRUE / FALSE o Yes / No son tratadas como dicotómicas.
Los valores NA se listan como “Unknown
Los atributos de etiqueta se imprimen por defecto.
Uno puede realizar más personalizaciones a la tabla.
Personalización del resultado de tbl_summary()
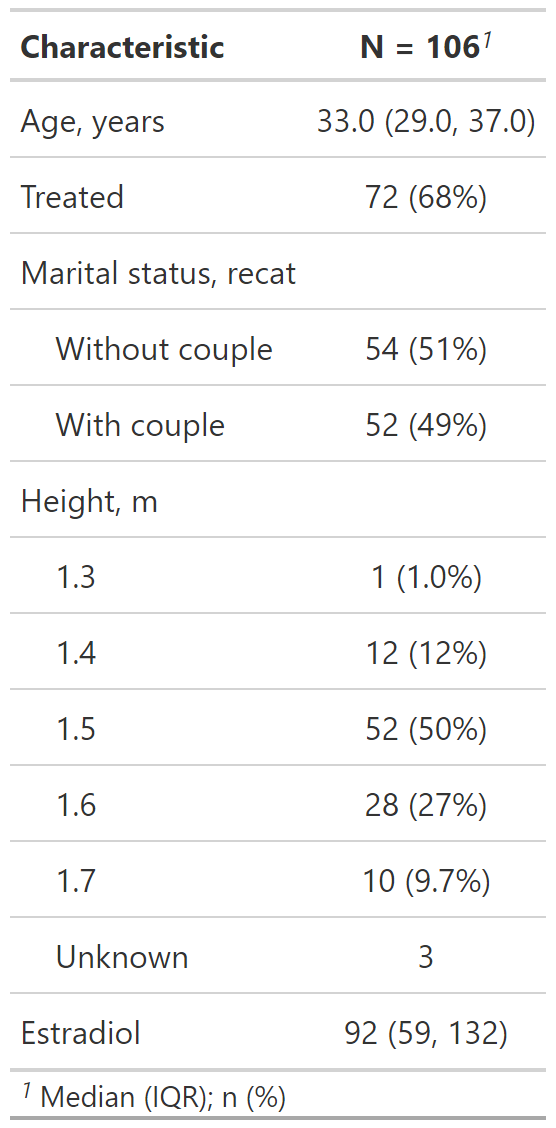
Personalización del resultado de tbl_summary()
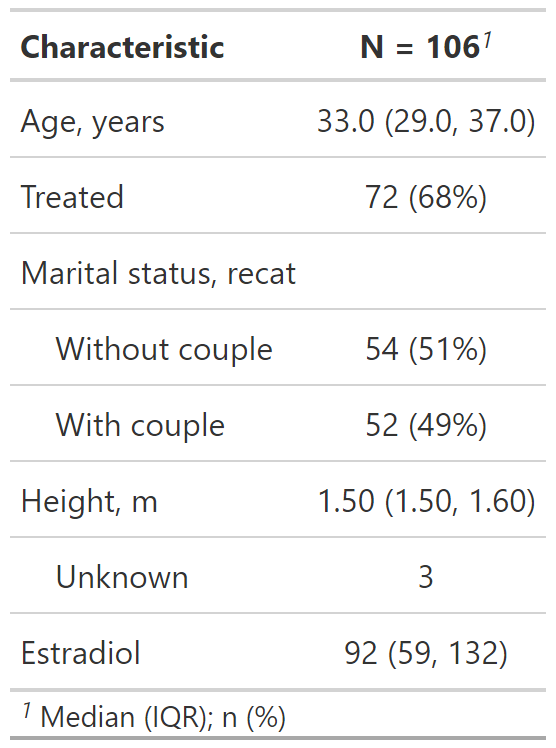
Personalización del resultado de tbl_summary()
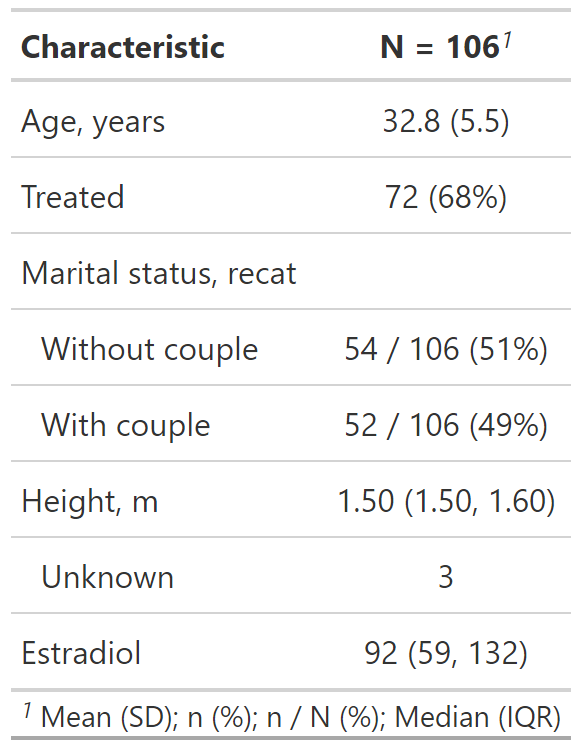
Personalización del resultado de tbl_summary()
datos %>%
select(age, treated, married2, height, e2) %>%
tbl_summary(
type = list(height ~ "continuous"),
statistic = list(
c(age, height) ~ "{mean} ({sd})",
c(married2, treated) ~ "{n} / {N} ({p}%)"
)
)type: Especifica el tipo de variable para el resumen.
statistic: Personaliza los estadísticos reportados.
- Usar c() para varias variables.
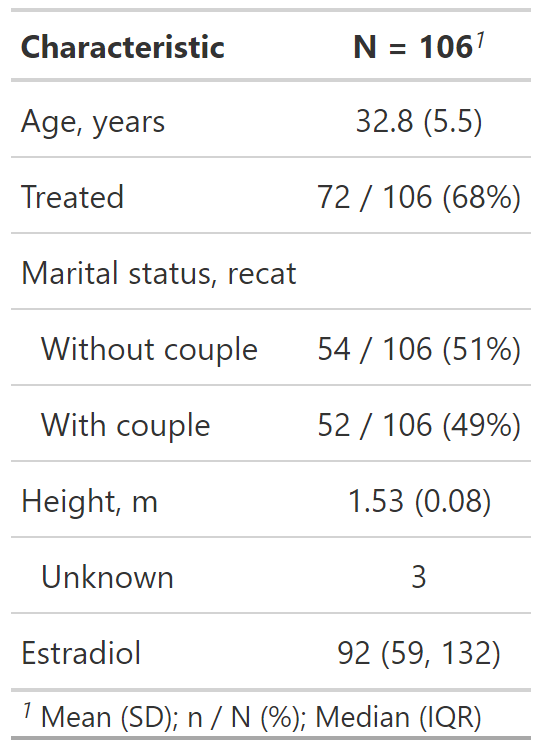
Personalización del resultado de tbl_summary()
datos %>%
select(age, treated, married2, height, e2) %>%
tbl_summary(
type = list(c(age, height) ~ "continuous2"),
statistic = list(
c(age, height) ~ c("{mean} ({sd})",
"{median} ({p25} - {p75})"),
c(married2, treated) ~ "{n} / {N} ({p}%)"
)
)type: Especifica el tipo de variable para el resumen.
statistic: Personaliza los estadísticos reportados.
Usar c() para varias variables.
Si queremos reportar más estadísticos en variables numéricas usamos continuous2
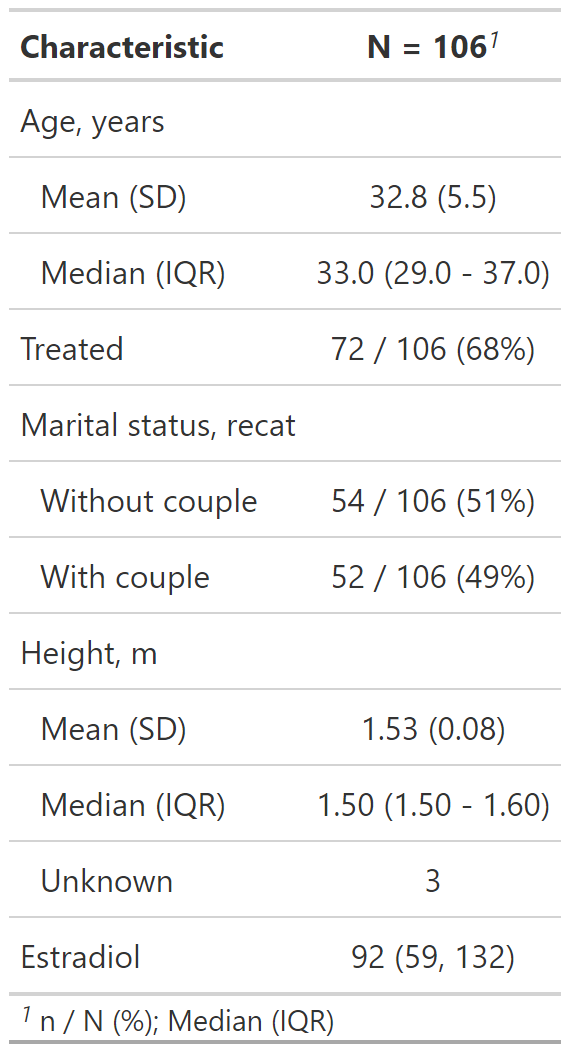
Personalización del resultado de tbl_summary()
datos %>%
select(age, treated, married2, height, e2) %>%
tbl_summary(
type = list(c(age, height) ~ "continuous2"),
statistic = list(
c(age, height) ~ c("{mean} ({sd})",
"{median} ({p25} - {p75})",
"{min} - {max}"),
c(married2, treated) ~ "{n} / {N} ({p}%)"
)
)type: Especifica el tipo de variable para el resumen.
statistic: Personaliza los estadísticos reportados.
Usar c() para varias variables.
Si queremos reportar más estadísticos en variables numéricas usamos continuous2
- Podemos ponerle cuantos estadísticos queramos.
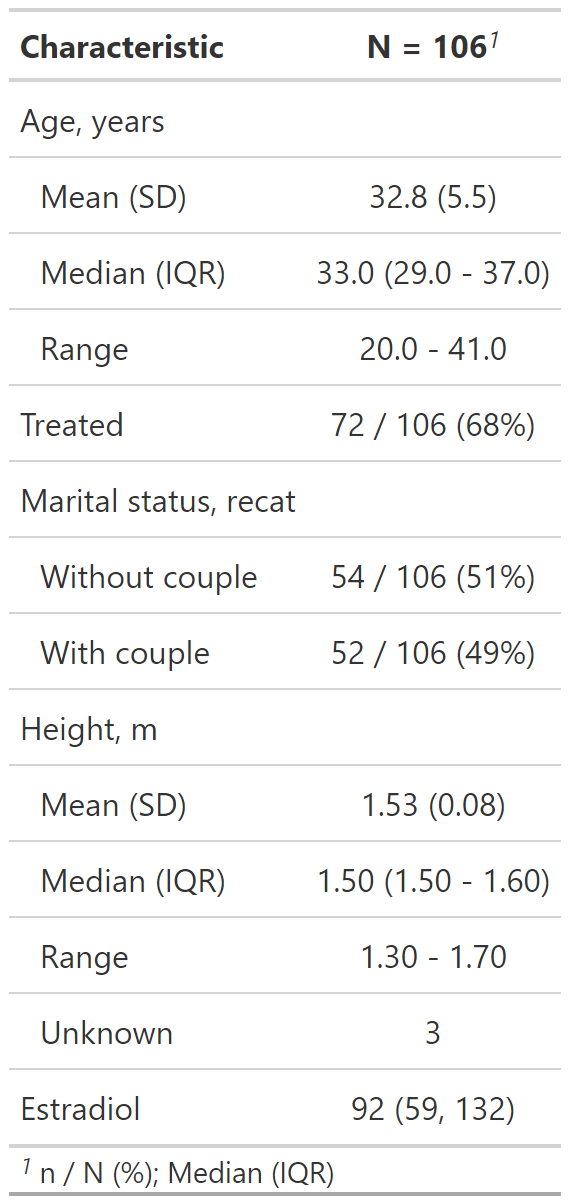
Personalización del resultado de tbl_summary()
datos %>%
select(age, treated, married2, height, e2) %>%
tbl_summary(
type = list(c(age, height) ~ "continuous2"),
statistic = list(
c(age, height) ~ c("{mean} ({sd})", "{min} - {max}"),
c(e2) ~ c("{median} ({p25} - {p75})",
"{min} - {max}"),
c(married2, treated) ~ "{n} / {N} ({p}%)"
)
) type: Especifica el tipo de variable para el resumen.
statistic: Personaliza los estadísticos reportados.
Usar c() para varias variables.
Si queremos reportar más estadísticos en variables numéricas usamos continuous2
Podemos ponerle cuantos estadísticos queramos.
Podemos tener diferentes combinaciones de estadísticos.
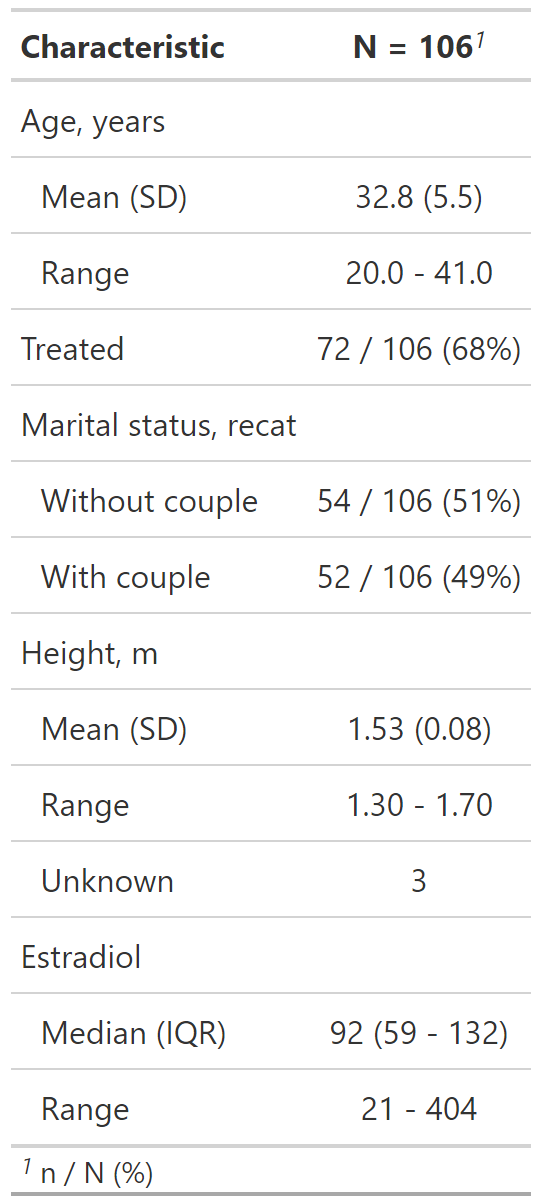
Personalización del resultado de tbl_summary()
datos %>%
select(age, treated, married2, height, e2) %>%
tbl_summary(
type = list(c(age, height, e2) ~ "continuous2"),
statistic = list(
c(age, height) ~ c("{mean} ({sd})", "{min} - {max}"),
c(e2) ~ c("{median} ({p25} - {p75})",
"{min} - {max}"),
c(married2, treated) ~ "{n} / {N} ({p}%)"
),
label = list(
treated ~ "Treated with supplement", e2 ~ "Estradiol, UI",
married2 ~ "Marital status"
)
)type: Especifica el tipo de variable para el resumen.
statistic: Personaliza los estadísticos reportados.
label: Cambia o personaliza la etiqueta de la variable.
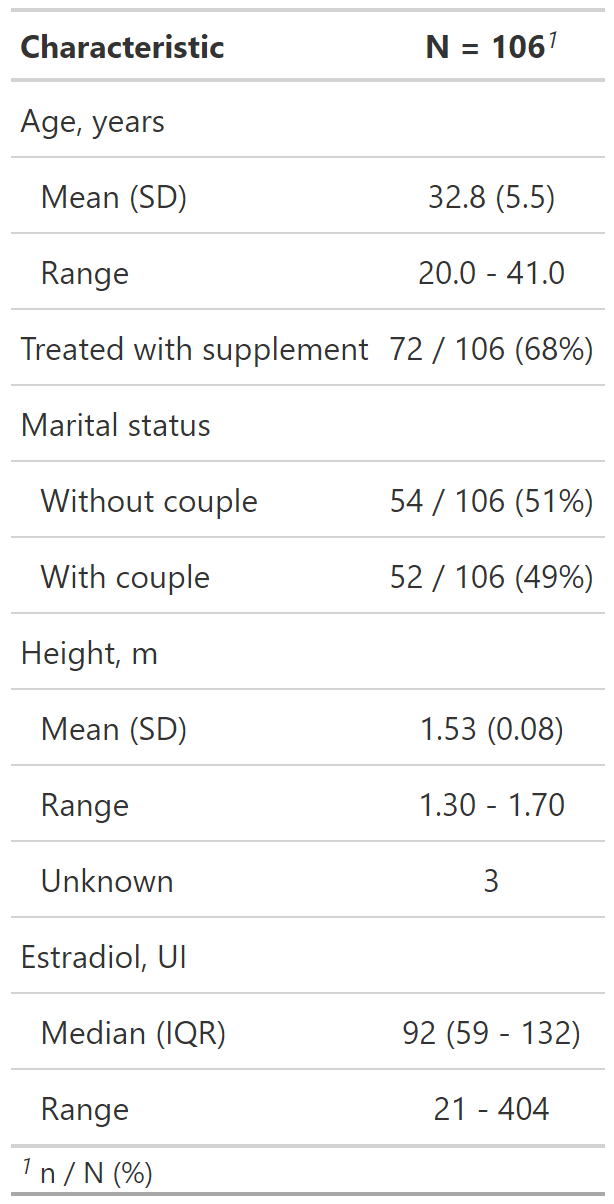
Personalización del resultado de tbl_summary()
datos %>%
select(age, treated, married2, height, e2) %>%
tbl_summary(
type = list(c(age, height, e2) ~ "continuous2"),
statistic = list(
c(age, height) ~ c("{mean} ({sd})", "{min} - {max}"),
c(e2) ~ c("{median} ({p25} - {p75})",
"{min} - {max}"),
c(married2, treated) ~ "{n} / {N} ({p}%)"
),
label = list(
treated ~ "Treated with supplement", e2 ~ "Estradiol, UI",
married2 ~ "Marital status"
),
digits = list(
c(age) ~ 1, c(height, e2) ~ 2, c(married2, treated) ~ 1
)
)type: Especifica el tipo de variable para el resumen.
statistic: Personaliza los estadísticos reportados.
label: Cambia o personaliza la etiqueta de la variable.
digit: Especifica el número de decimales de redondeo.
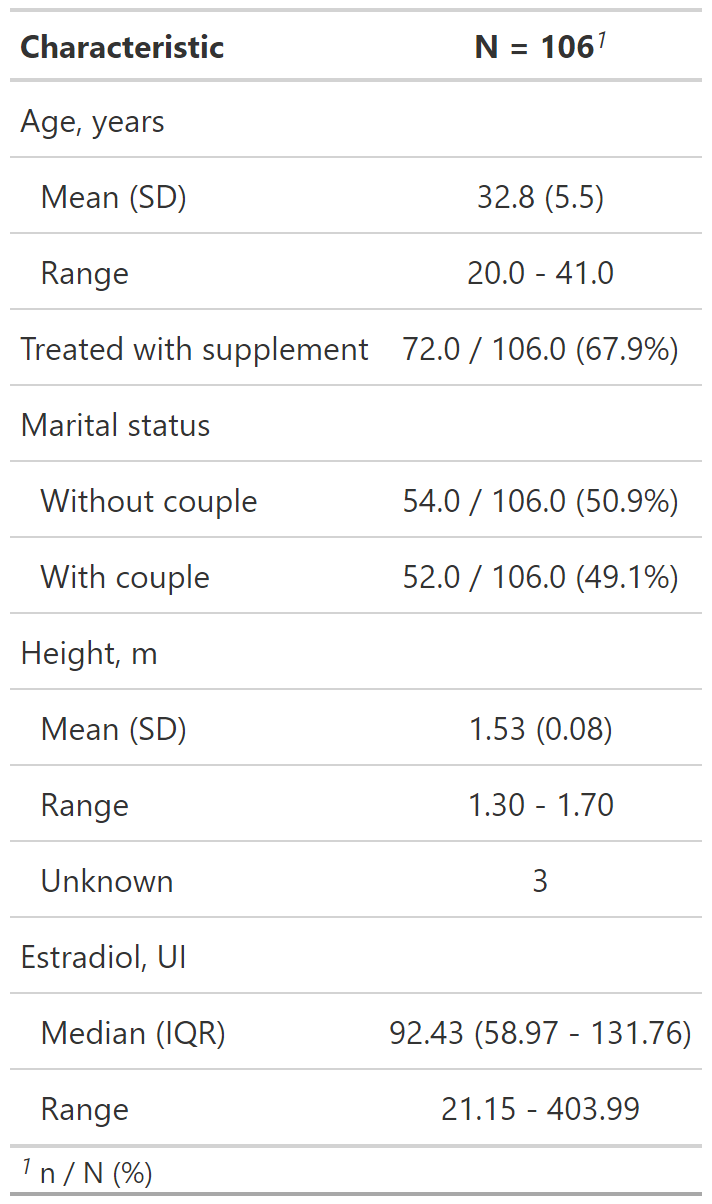
Reporte de datos perdidos con tbl_summary()
datos %>%
select(age, treated, married2, height, e2) %>%
tbl_summary(
type = list(c(age, height, e2) ~ "continuous2"),
statistic = list(
c(age, height) ~ c("{mean} ({sd})", "{min} - {max}"),
c(e2) ~ c("{median} ({p25} - {p75})", "{min} - {max}"),
c(married2, treated) ~ "{n} / {N} ({p}%)"
),
label = list(
treated ~ "Treated with supplement", e2 ~ "Estradiol, UI",
married2 ~ "Marital status"
),
digits = list(
c(age) ~ 1, c(height, e2) ~ 2, c(married2, treated) ~ 1
),
missing_text = "Missing data"
) - misisng_text: Permite editar la etiqueta de missing (Unknown por defecto).
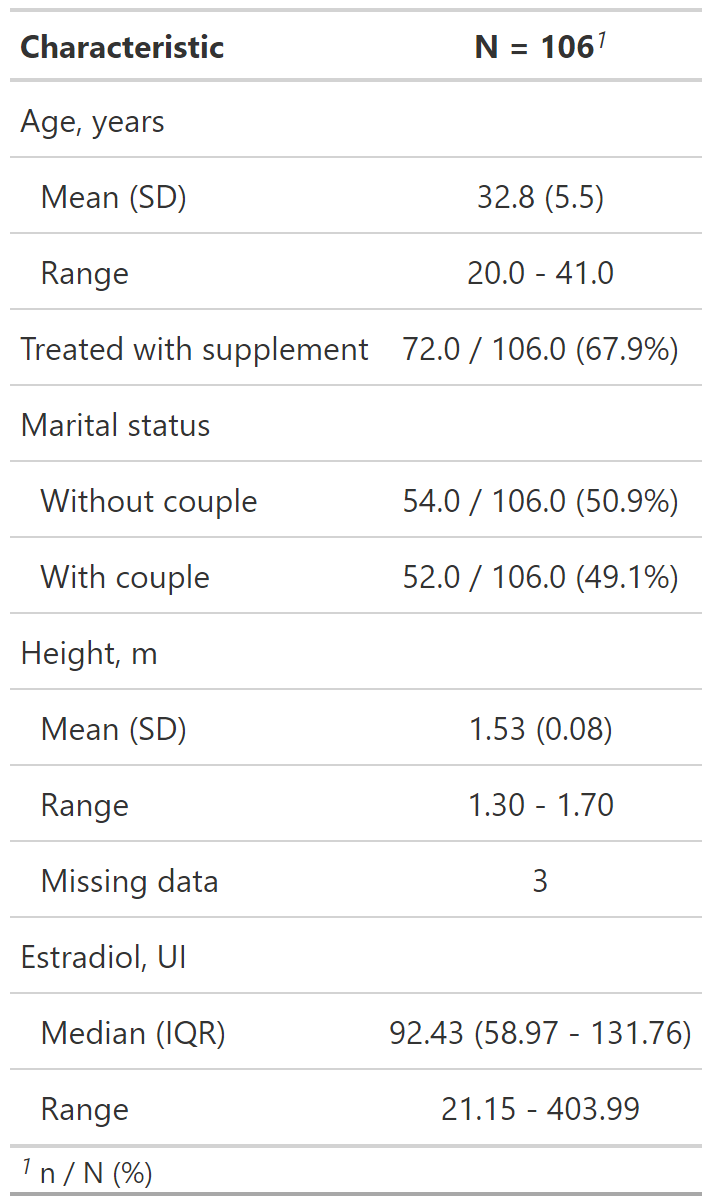
Reporte de datos perdidos con tbl_summary()
datos %>%
select(age, treated, married2, height, e2) %>%
tbl_summary(
type = list(c(age, height, e2) ~ "continuous2"),
statistic = list(
c(age, height) ~ c("{mean} ({sd})", "{min} - {max}"),
c(e2) ~ c("{median} ({p25} - {p75})", "{min} - {max}"),
c(married2, treated) ~ "{n} / {N} ({p}%)"
),
label = list(
treated ~ "Treated with supplement", e2 ~ "Estradiol, UI",
married2 ~ "Marital status"
),
digits = list(
c(age) ~ 1, c(height, e2) ~ 2, c(married2, treated) ~ 1
),
missing = "always", missing_text = "Missing data"
) misisng_text: Permite editar la etiqueta de missing (Unknown por defecto).
missing: Por defecto se presentan los datos perdidos solo si la variable los tiene “ifany”.
- missing = “always” siempre presenta datos perdidos.
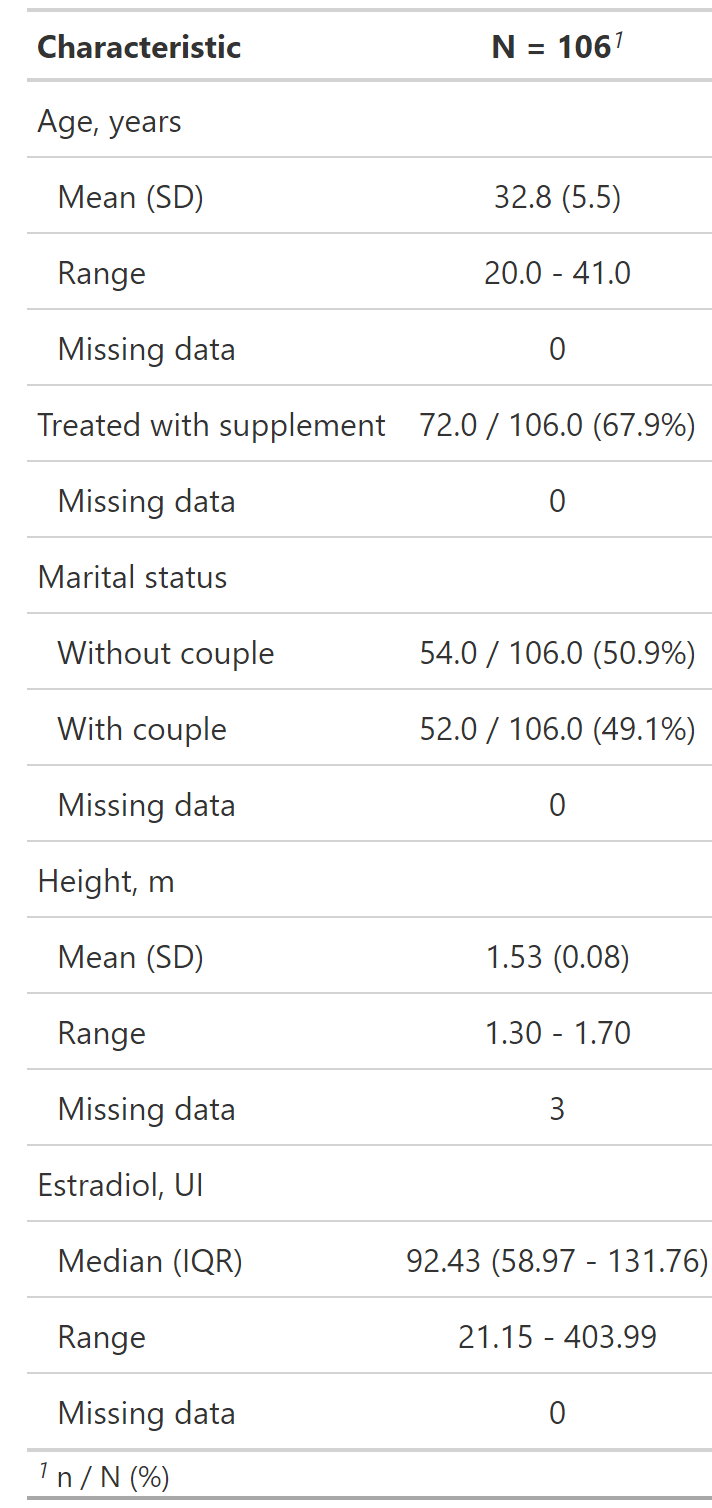
Reporte de datos perdidos con tbl_summary()
datos %>%
select(age, treated, married2, height, e2) %>%
tbl_summary(
type = list(c(age, height, e2) ~ "continuous2"),
statistic = list(
c(age, height) ~ c("{mean} ({sd})", "{min} - {max}"),
c(e2) ~ c("{median} ({p25} - {p75})", "{min} - {max}"),
c(married2, treated) ~ "{n} / {N} ({p}%)"
),
label = list(
treated ~ "Treated with supplement", e2 ~ "Estradiol, UI",
married2 ~ "Marital status"
),
digits = list(
c(age) ~ 1, c(height, e2) ~ 2, c(married2, treated) ~ 1
),
missing = "no"
) misisng_text: Permite editar la etiqueta de missing (Unknown por defecto).
missing: Por defecto se presentan los datos perdidos solo si la variable los tiene “ifany”.
- missing = “always” siempre presenta datos perdidos, así la variable no los tenga.
- missing = “no” nunca presenta datos perdidos, así la variable los tenga.
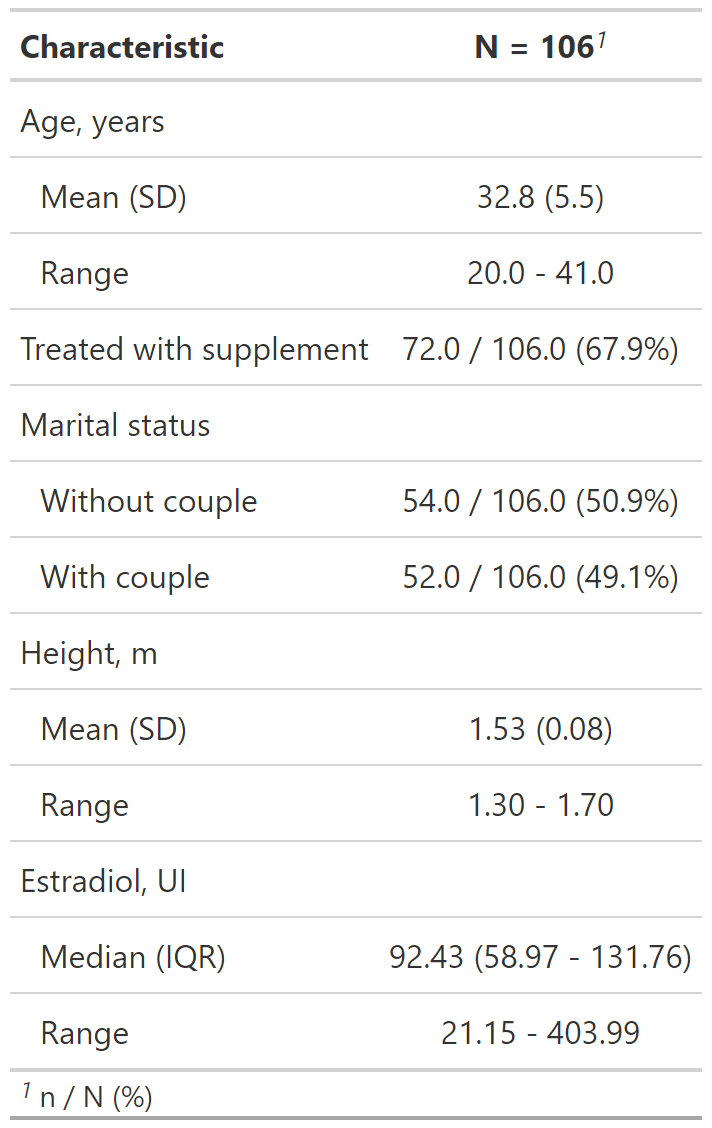
En resumen: {gtsummary} + fórmulas
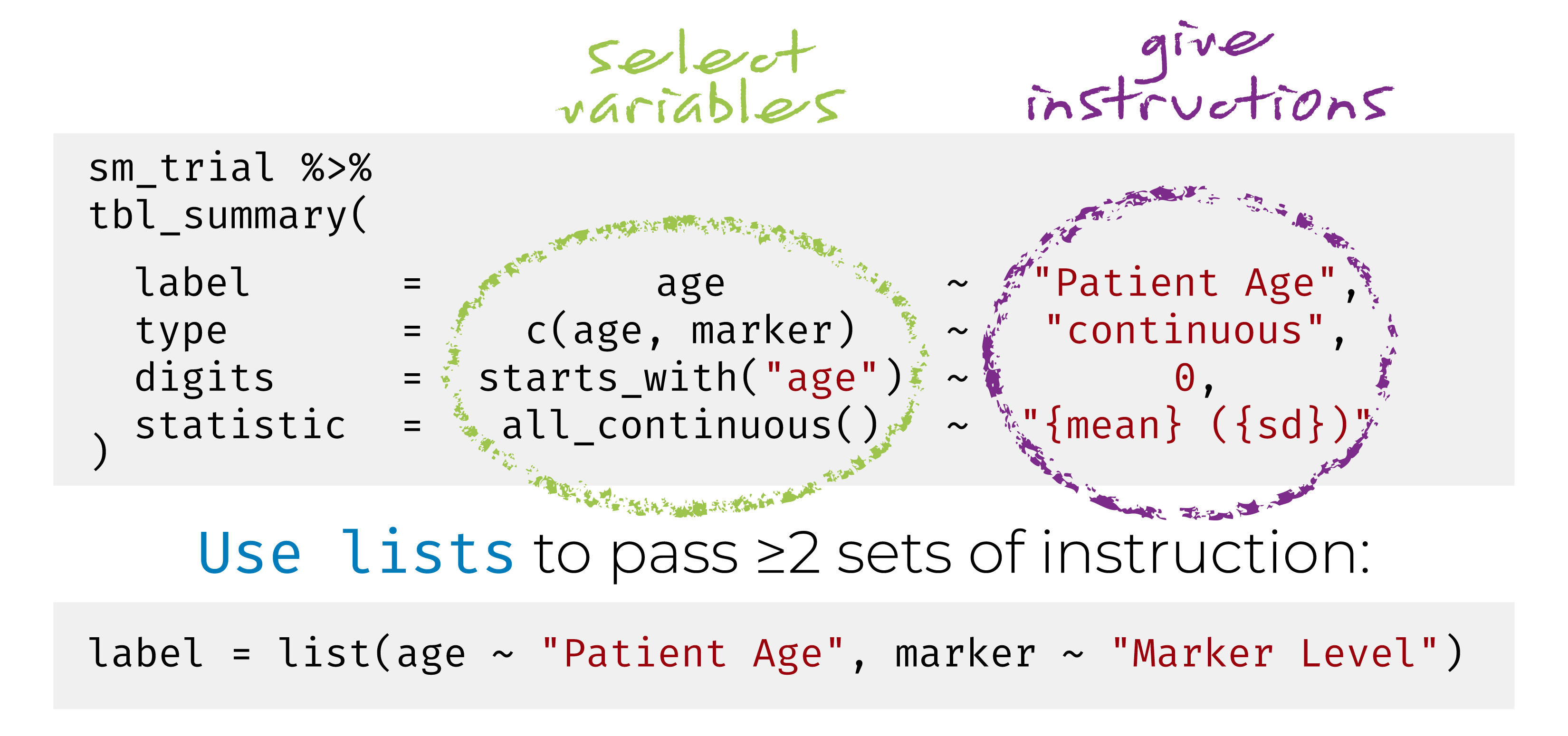
Personzalización con bold_() / italicize_()
Personzalización con bold_() / italicize_()
- bold_labels(): negrita a las etiquetas de las variables
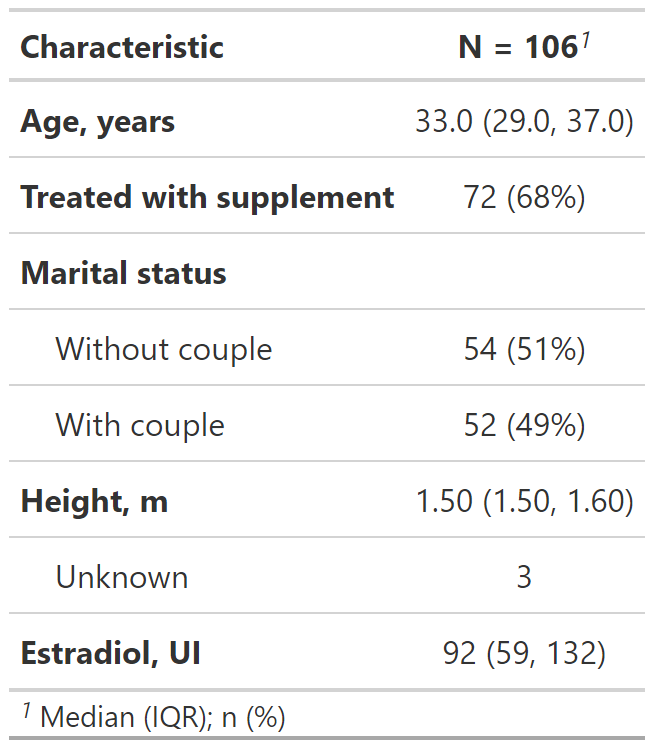
Personzalización con bold_*() / italicize_*()
bold_labels(): negrita a las etiquetas de las variables
italicize_levels(): cursiva a los niveles (valores) de las variables
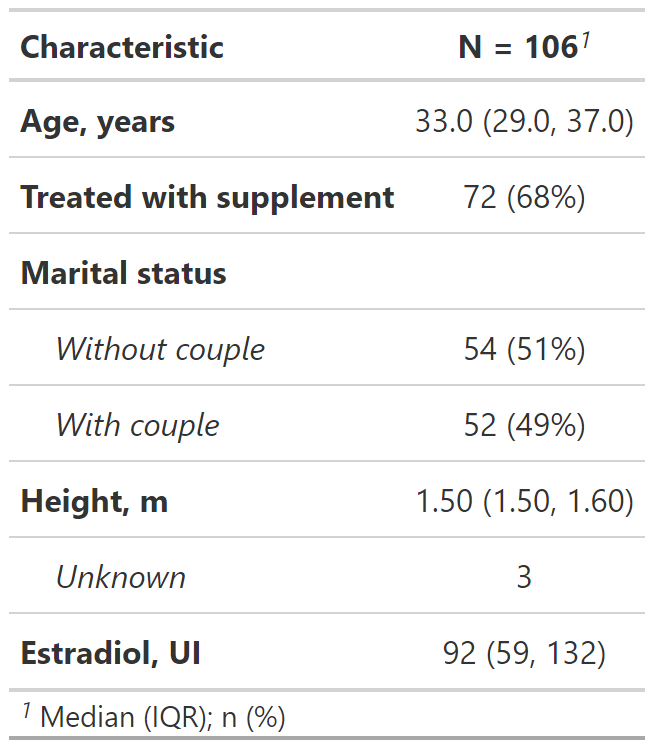
Guardar tabla como documento MS Word
Se puede descargar la tabla en formato MS. Word para reporte reproducible.
Primero se guarda como un objeto de R:
Guardar tabla como documento MS Word
Se puede descargar la tabla en formato MS. Word para reporte reproducible.
Primero se guarda como un objeto de R:
- Luego, al objeto se lo guarda como un archivo de MS Word.
Guardar tabla como documento MS Word
Se puede descargar la tabla en formato MS. Word para reporte reproducible.
Primero se guarda como un objeto de R:
- Luego, al objeto se lo guarda como un archivo de MS Word.
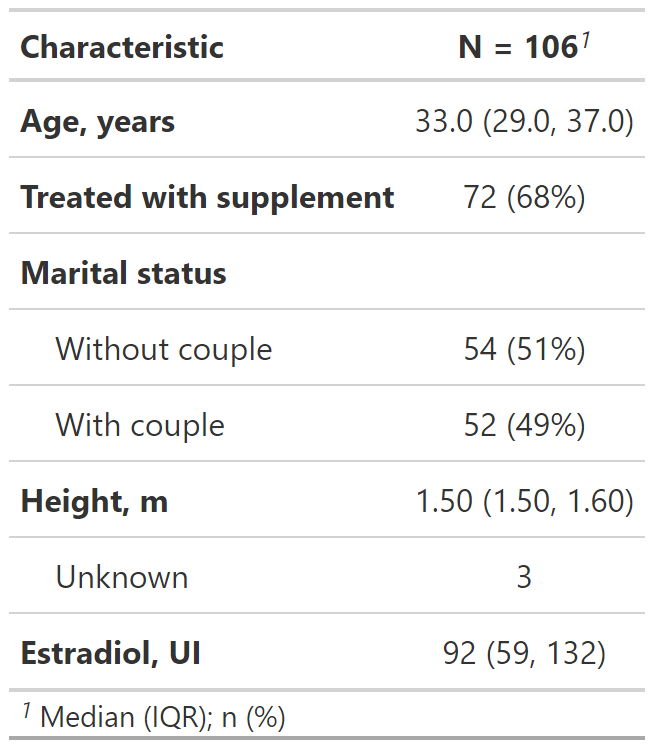
Guardar tabla como documento MS Word
Se puede descargar la tabla en formato MS. Word para reporte reproducible.
Primero se guarda como un objeto de R:
- Luego, al objeto se lo guarda como un archivo de MS Word.
Guardar tabla como documento MS Word
Se puede descargar la tabla en formato MS. Word para reporte reproducible.
Primero se guarda como un objeto de R:
- Luego, al objeto se lo guarda como un archivo de MS Word:
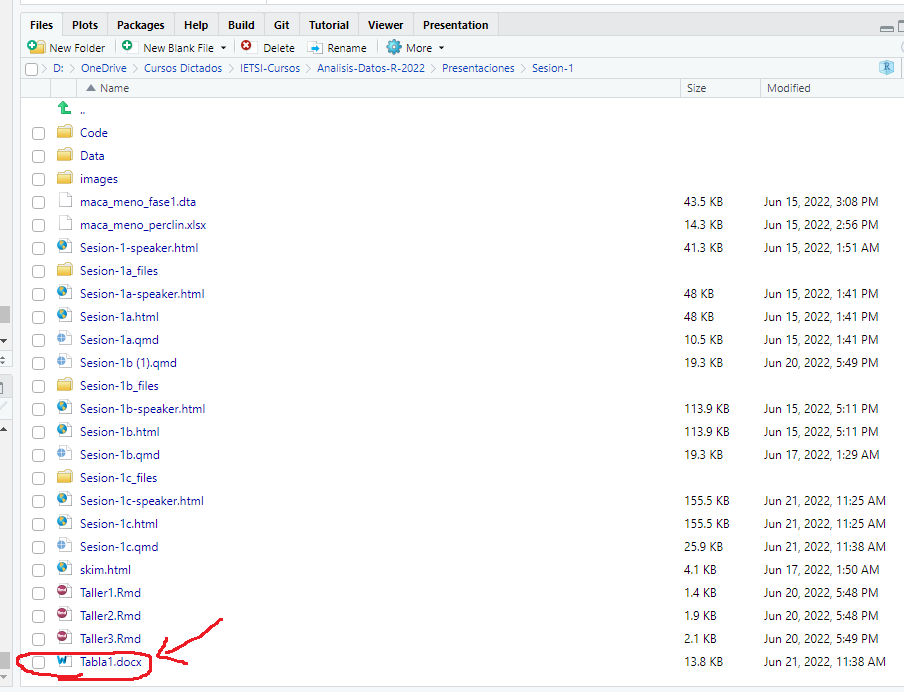
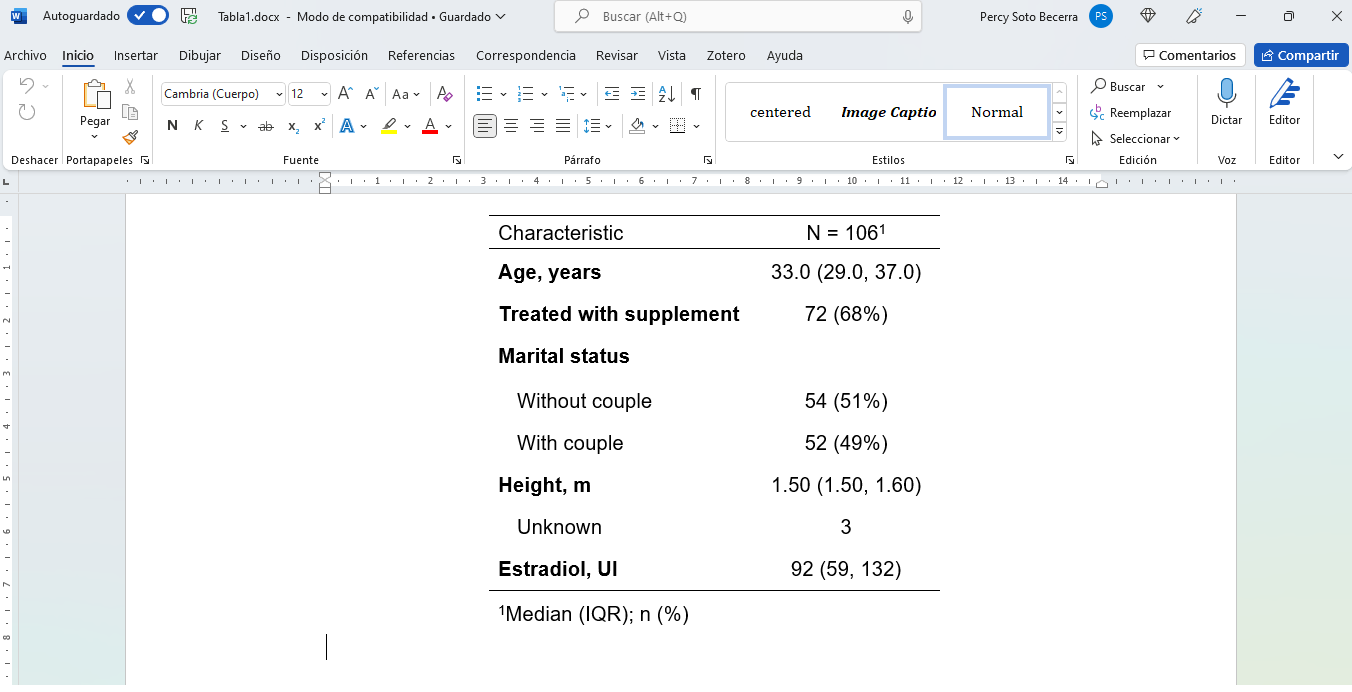
Guardar tabla como documento MS Word (cont.)
- El MS Word aparecerá en la carpeta del proyecto:
Guardar tabla como documento MS Word (cont.)
- Y la tabla en Word lucirá así:
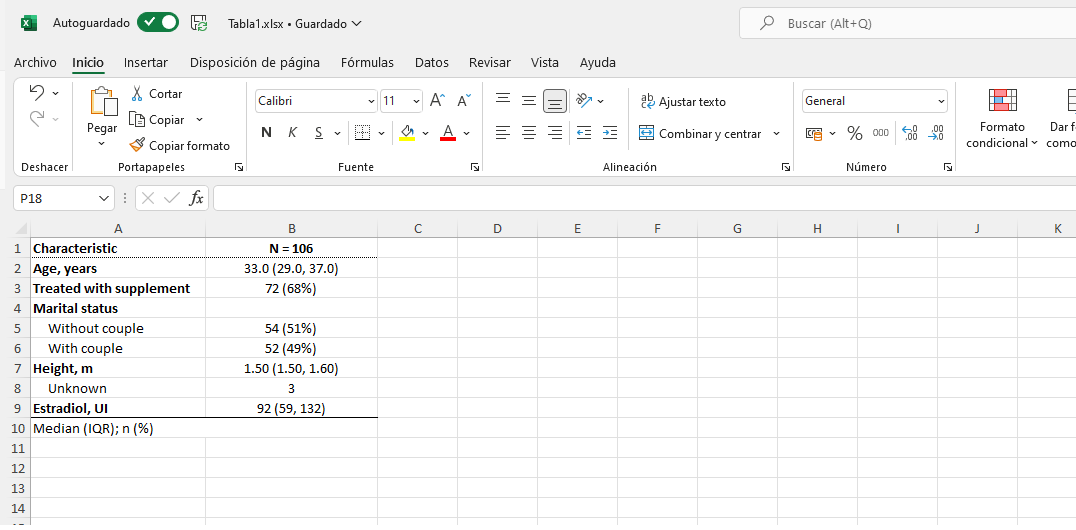
Guardar tabla como documento MS Excel
@psotob91
https://github.com/psotob91
percys1991@gmail.com