Sesión 8
Curso: R Aplicado a los Proyectos de Investigación
Percy Soto-Becerra, M.D., M.Sc(c)
InkaStats Data Science Solutions | Medical Branch
2022-10-19

Análisis de regresión
Conjunto de técnicas estadística para estimar la relación entre variables.
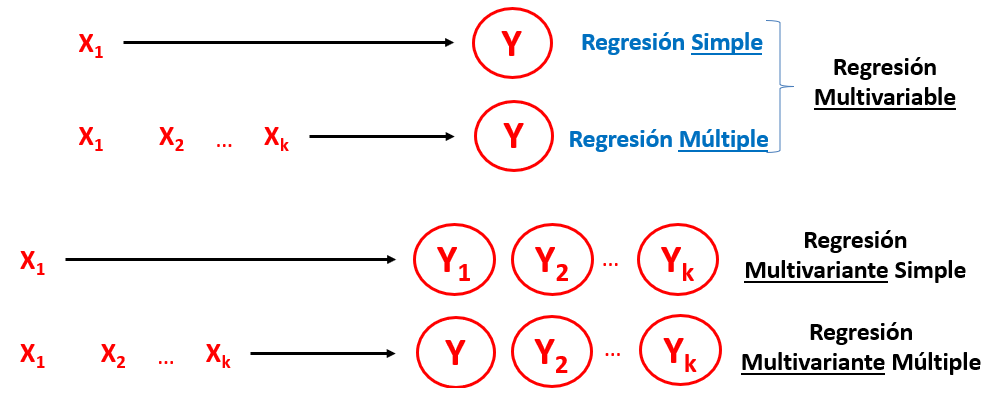
Modelos de regresión multivariable
Los modelos de regresión multivariable modelan una sola variable dependiente en función de una o más variables independientes.
- El desenlace define el tipo de regresión multivariable.
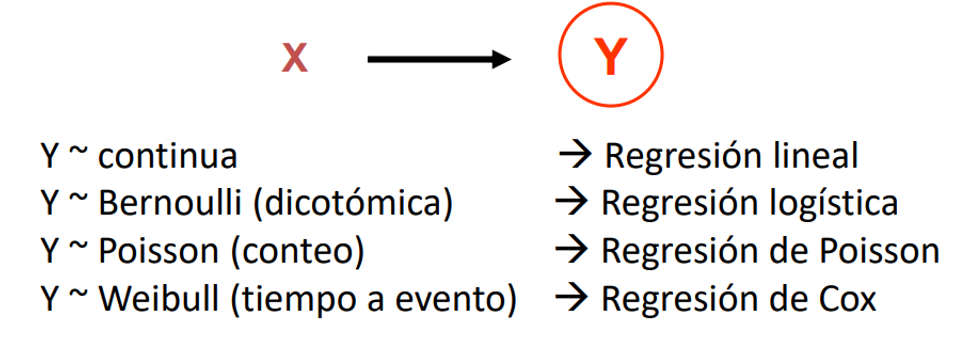
Propósitos del modelamiento
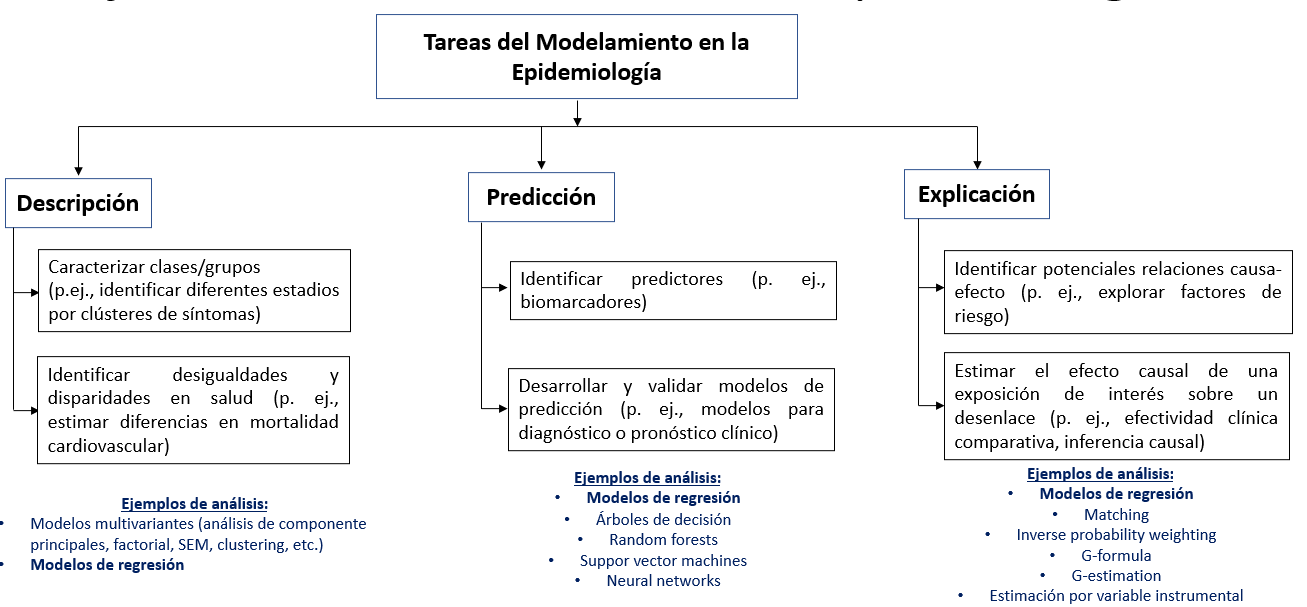
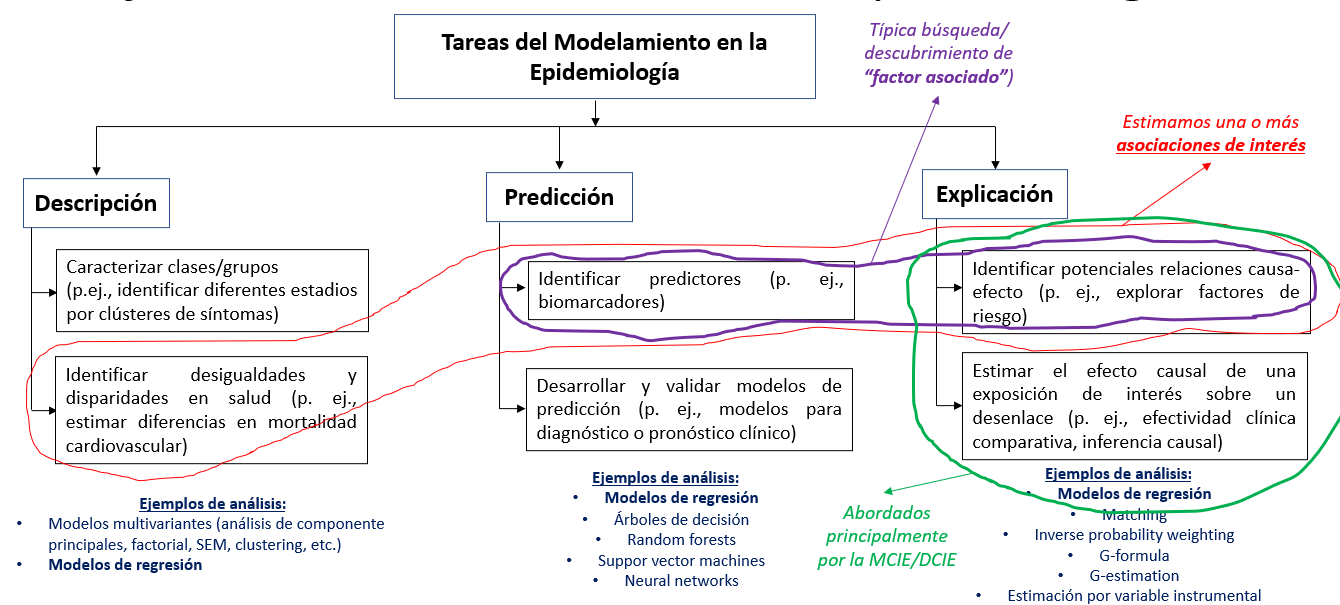
Propósitos del modelamiento (cont.)
Regresión Lineal
Método estadístico que modela la
relaciónentre unavariable continua (dependiente)y otrasvariables (independientes).
Relación entre dos variables
\(Y\) es
variable resultado(outcome), respuesta o dependiente.\(X\) es una
variable explicativa, predictora o regresora.En la figura, a mayor valor de \(X\), mayor valor de \(Y\).
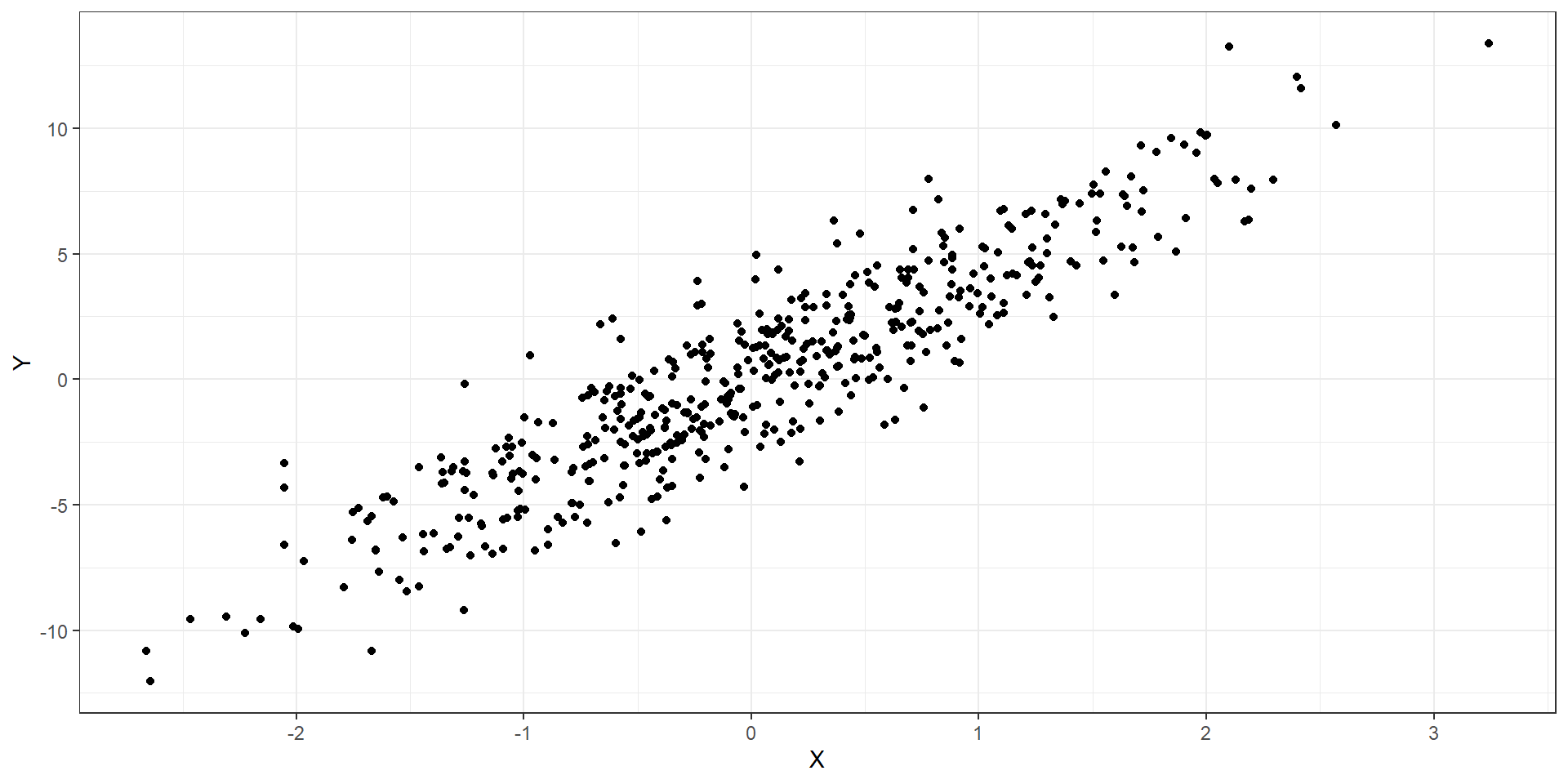
¿Cómo podemos resumir la relación entre ambas variables?
Podemos tratar de dibujar una
línea rectaqueresumala relación.Existen
infinitas rectas posiblesque podríamos trazar: ¿Cuál elegir?
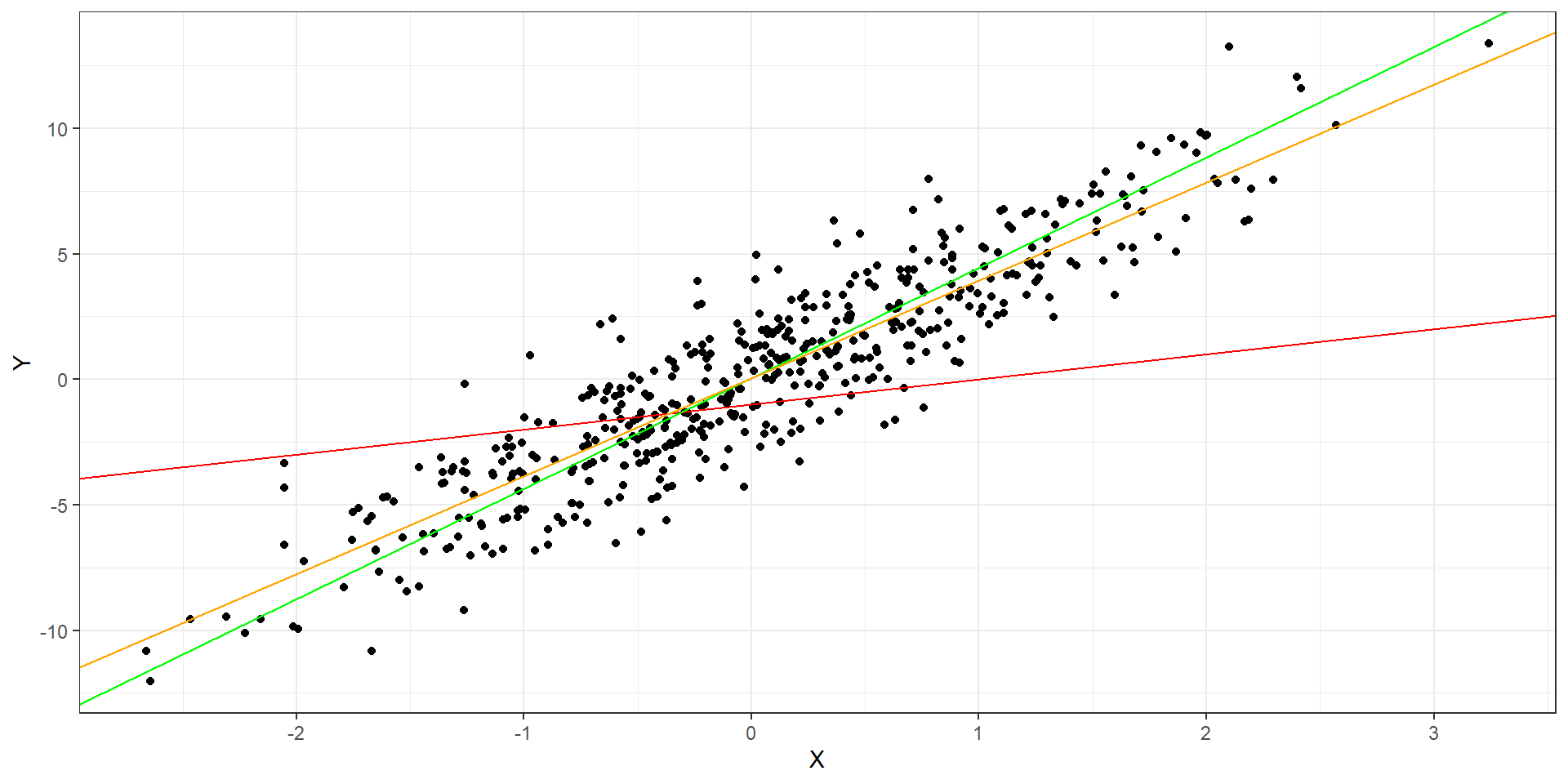
¿Cómo podemos resumir la relación entre ambas variables? (cont.)
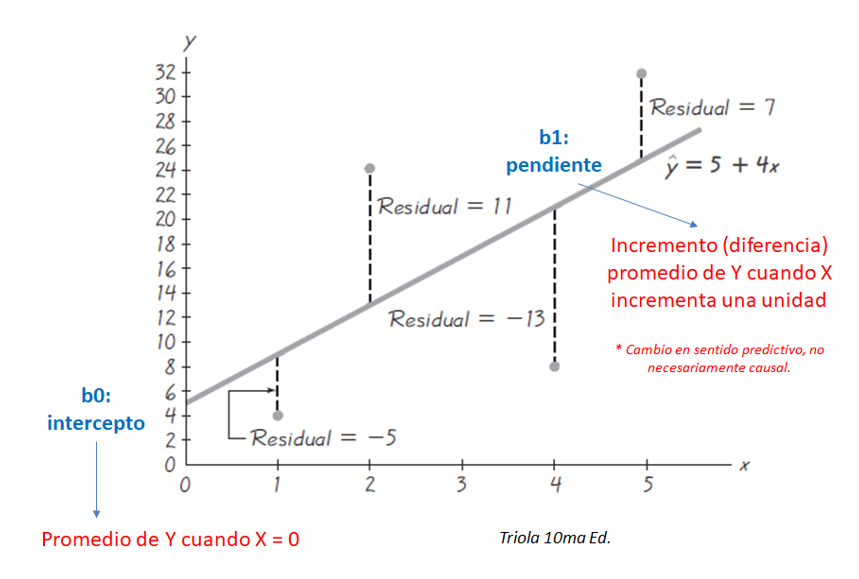
- Una opción sería elegir una
rectaque pase por elvalor más representativodel \(y_i\) en cada valor fijo de \(x_1\).- Una
rectaqueconectelospromedios condicionadosen \(x_1\)
- Una
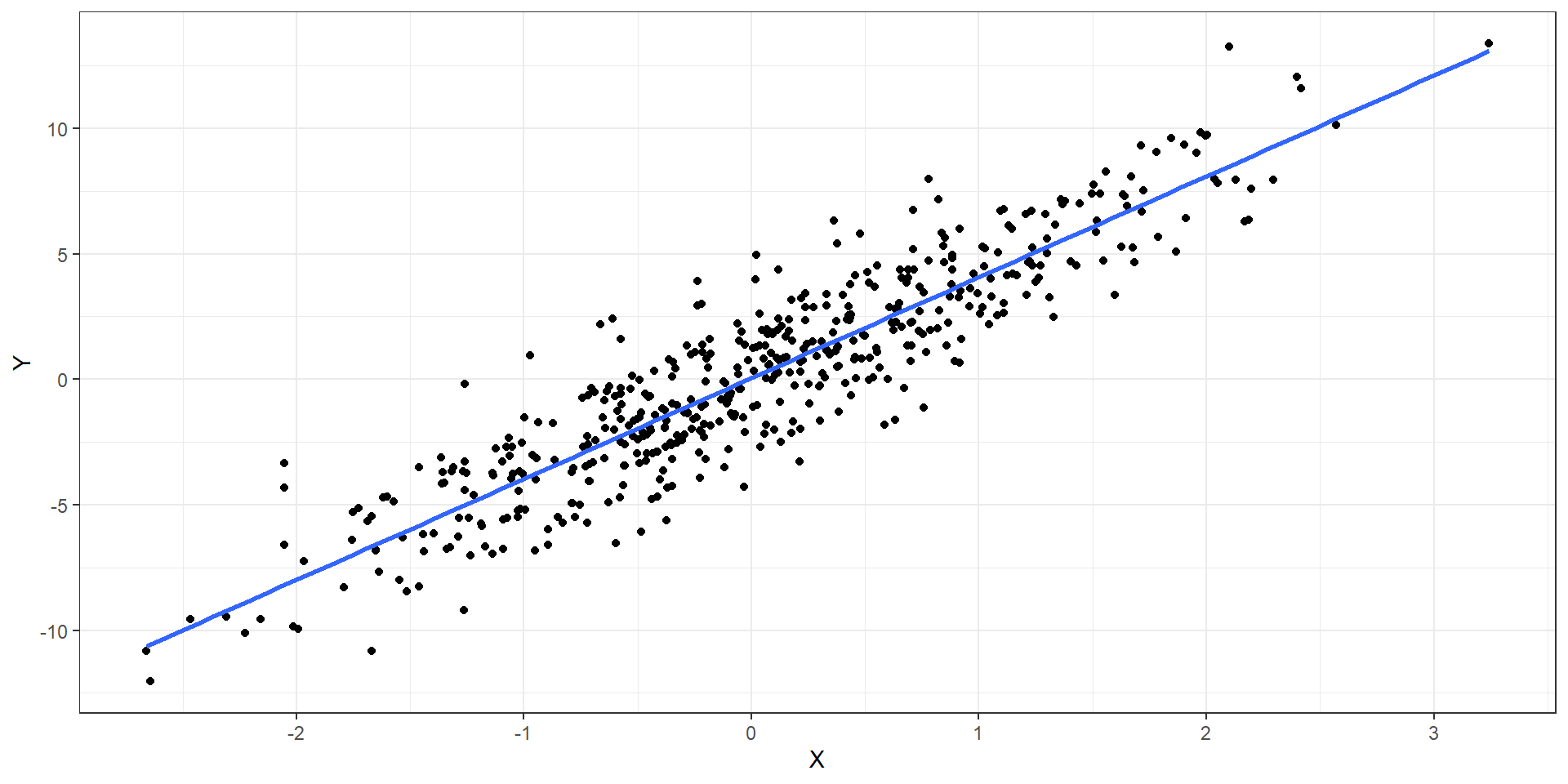
En resumen
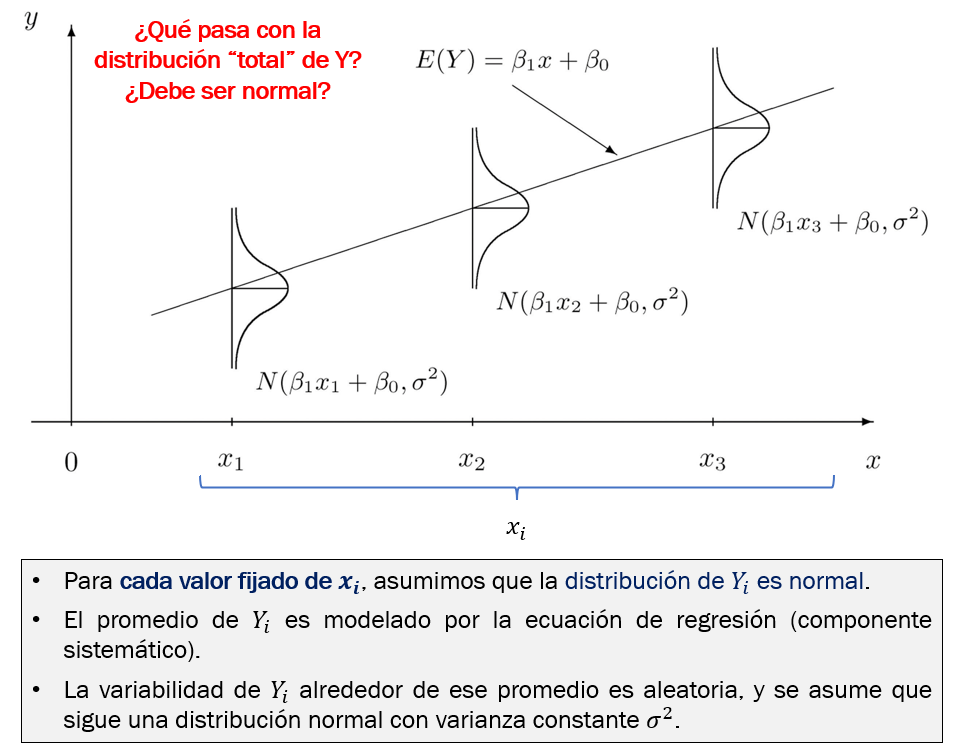
Estimación de ecuación de regresión
- En la práctica no conocemos los valores de los parámetros, así que los estimamos de nuestros datos.

Regresión Lineal Simple sobre variable explicativa categórica
Las
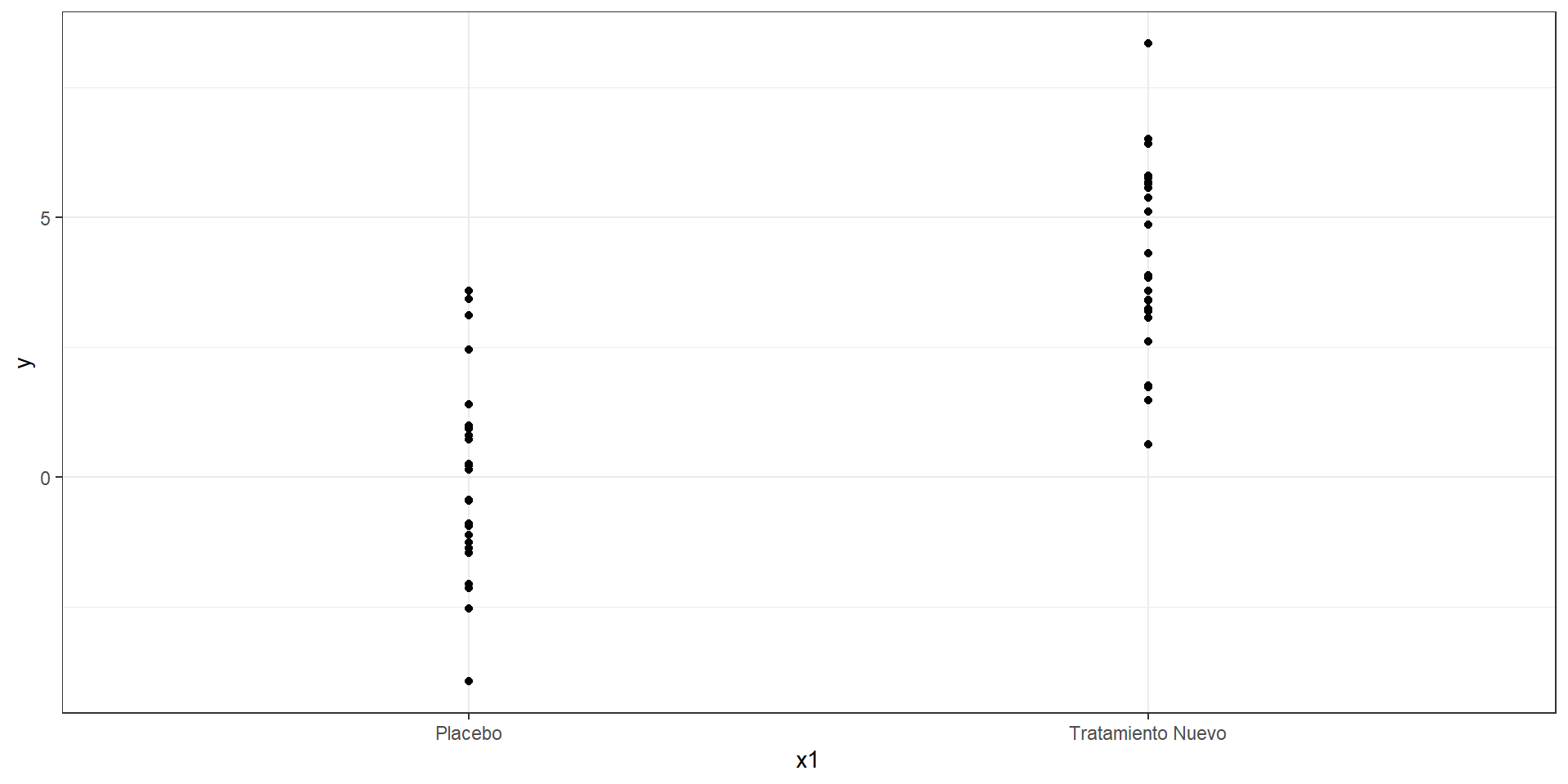
variables categóricasno son continuas, en cambio son discretas y asumen solo unos cuantos valores.¿Cómo estimar una medida de asociación cuando la variable explicativa es categórica?
Veamos el caso binario.
Regresión Lineal Simple sobre variable explicativa categórica (cont.)
Si la variable es
binaria, asignamos a una categoría elvalor de 1y a otra elvalor de 0.Asumiremos que la variable categórica es numérica para los efectos de todo cálculo.
Sin embargo, la interpretación se centrará en la comparación de categorías 0 y 1, nunca se interperará valores intermedios porquen o existen.
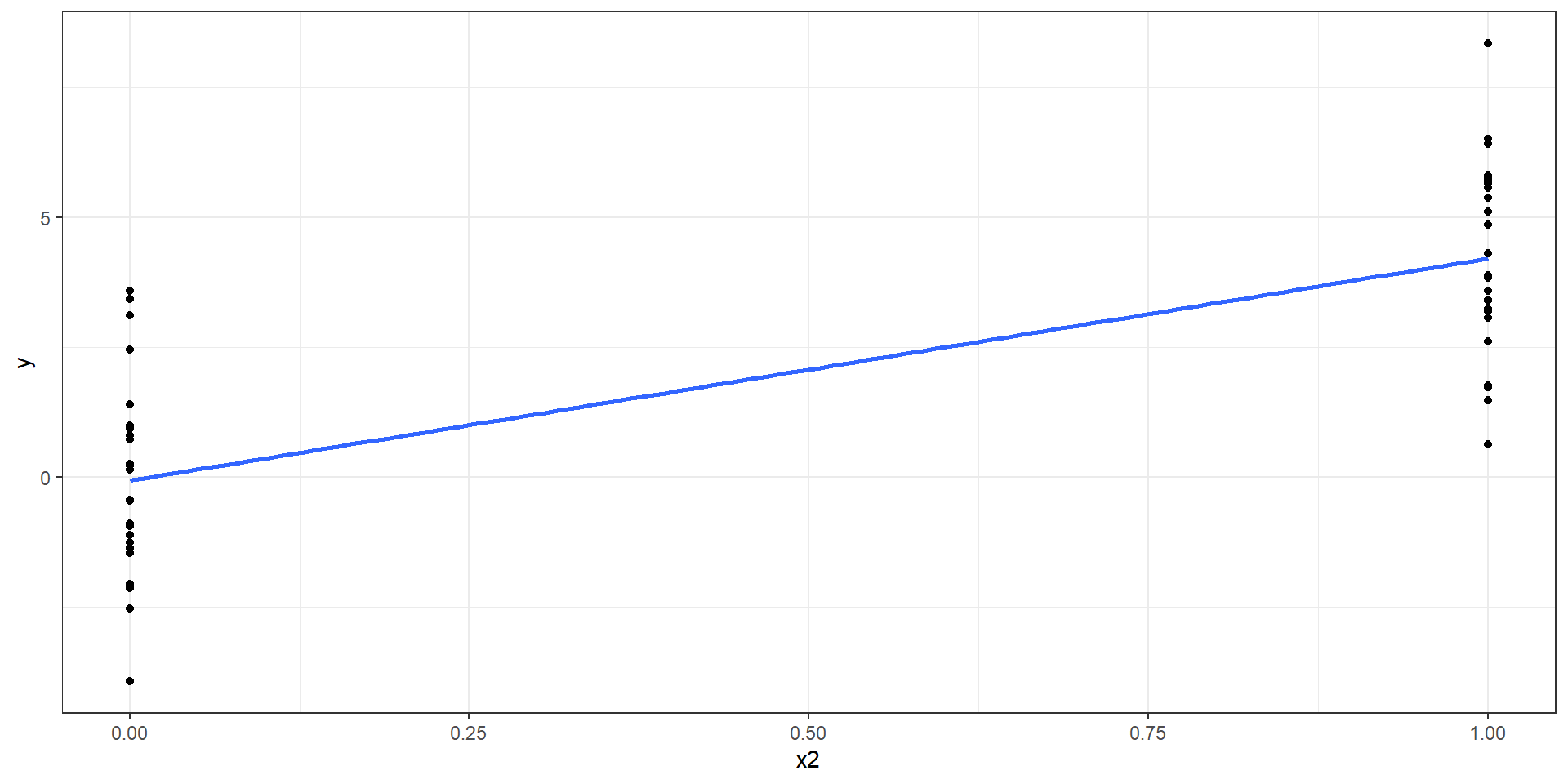
Regresión Lineal en gráficos
- La ecuación de la RLS representa una línea recta.
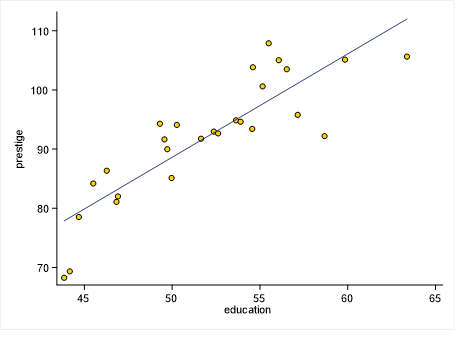
- La ecuación de la RLM con dos variables explicativas ya no representa una línea recta, sino un plano recto.
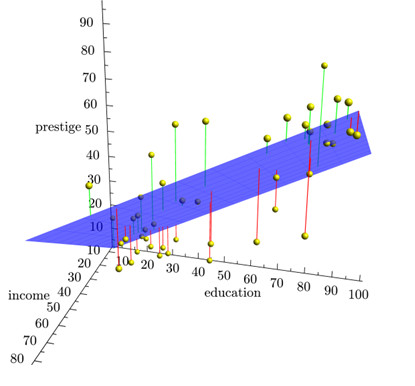
Genera un hiperplano recto.
No podemos imaginarnos una imagen de esto, pero sí podemos analizarlo a nivel estadístico.
- Algebra lineal proporciona herramientas para lidiar con esto usando matrices.
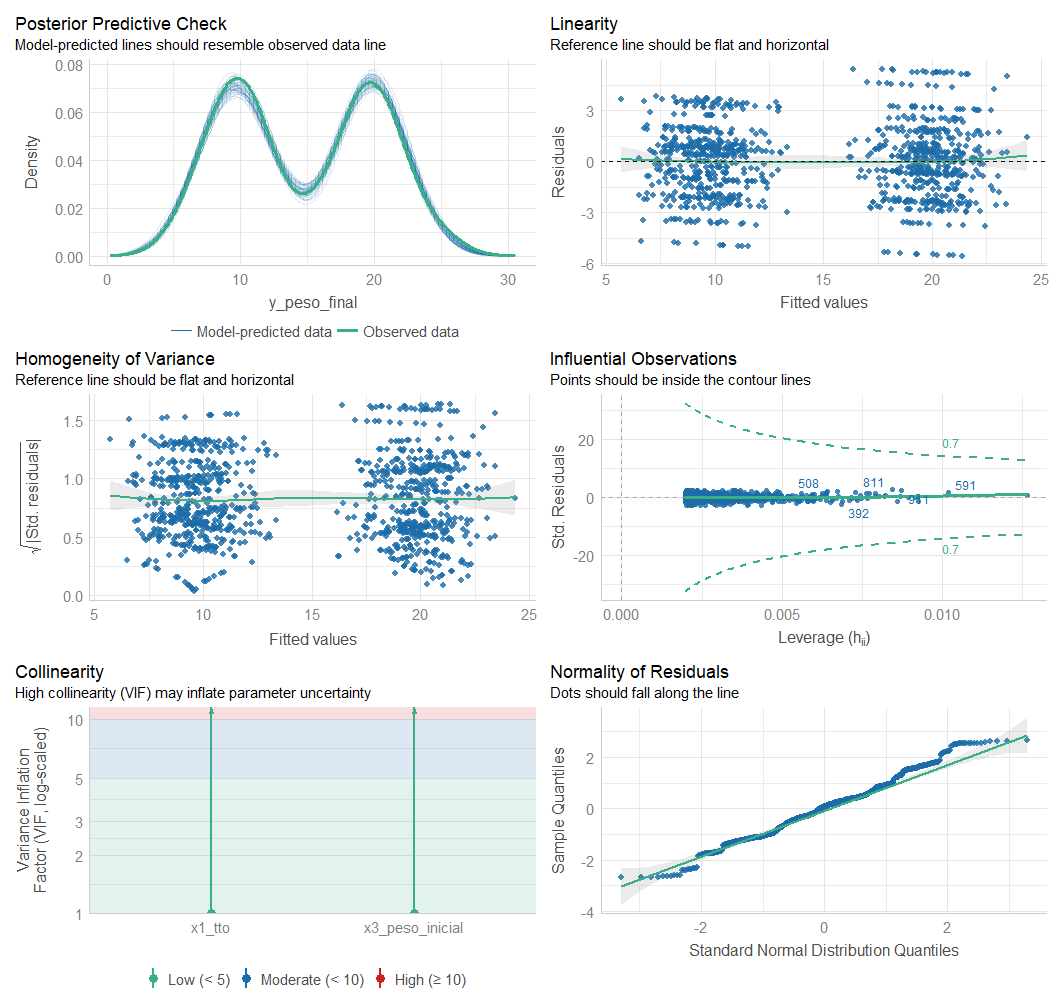
{broom} paso a paso
Residuos gráficamente
Algunas notas sobre los errores y residuos para evaluar supuestos
Función check_model() para evaluar supuestos (cont.)
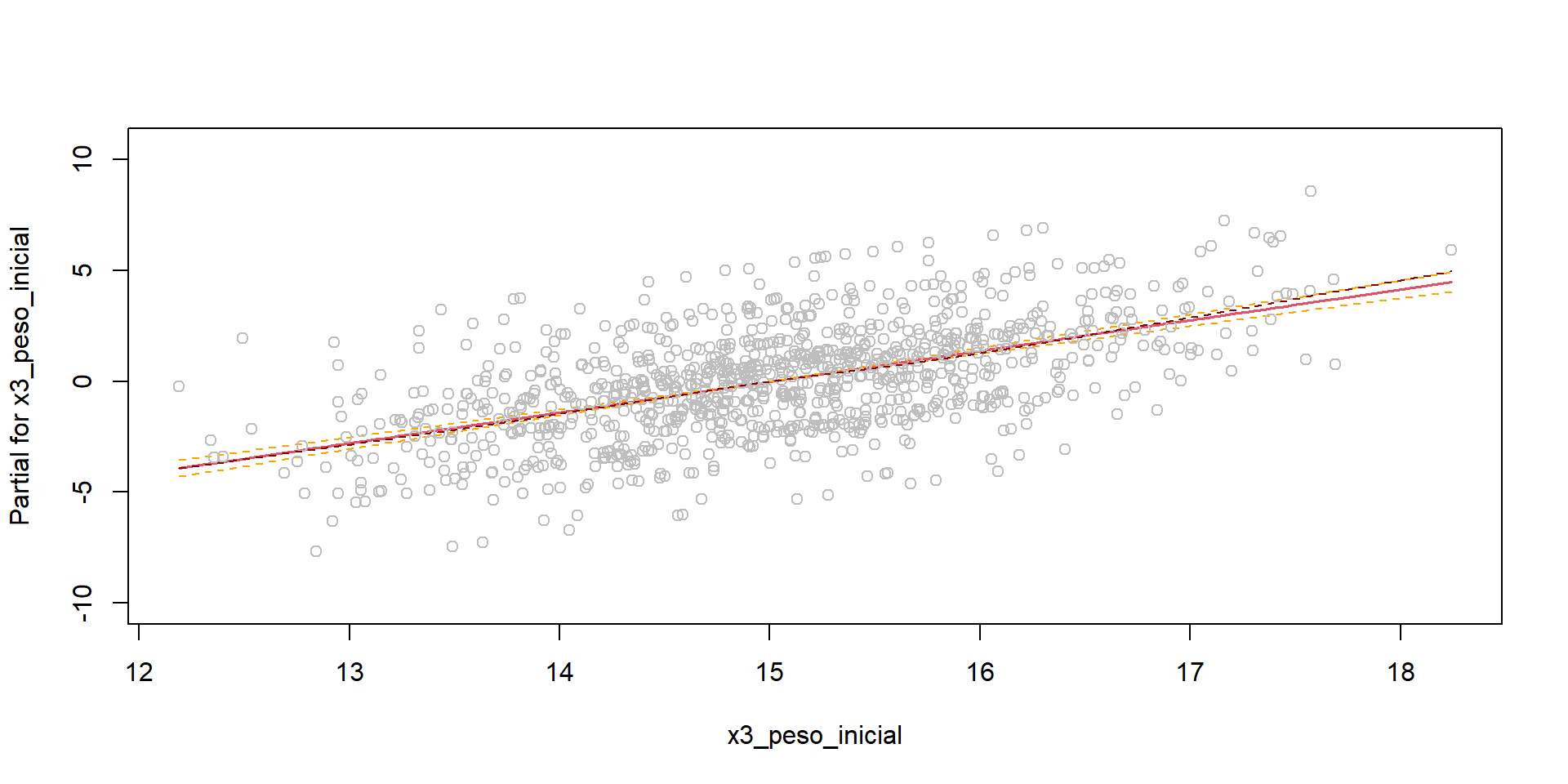
Linealidad con el paquete {car}
- Podemos usar gráficos de residuos parciales + Componente:
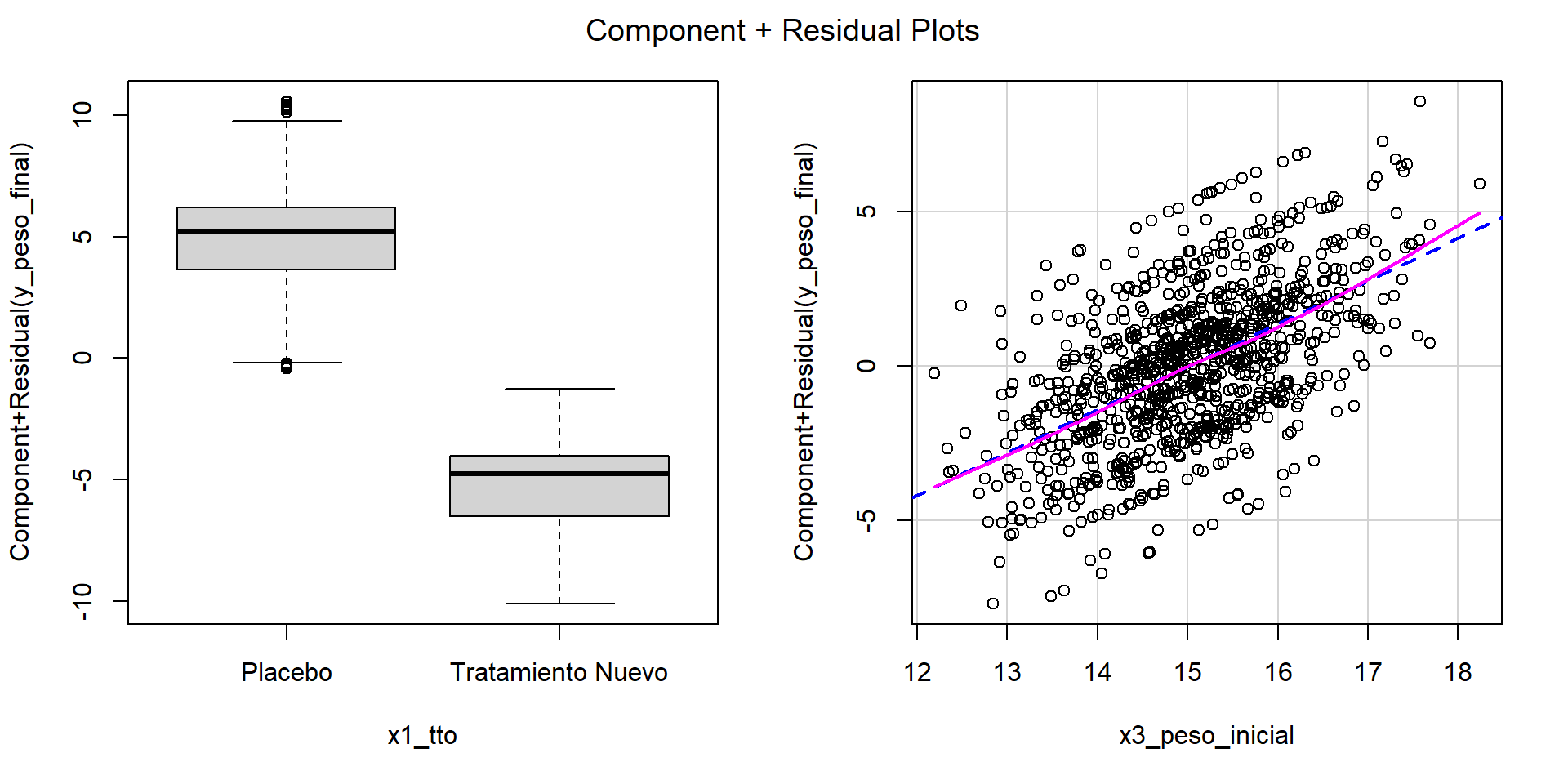
Linealidad con el paquete {car} (cont.)
- También podemos usar gráficos de variable agregada
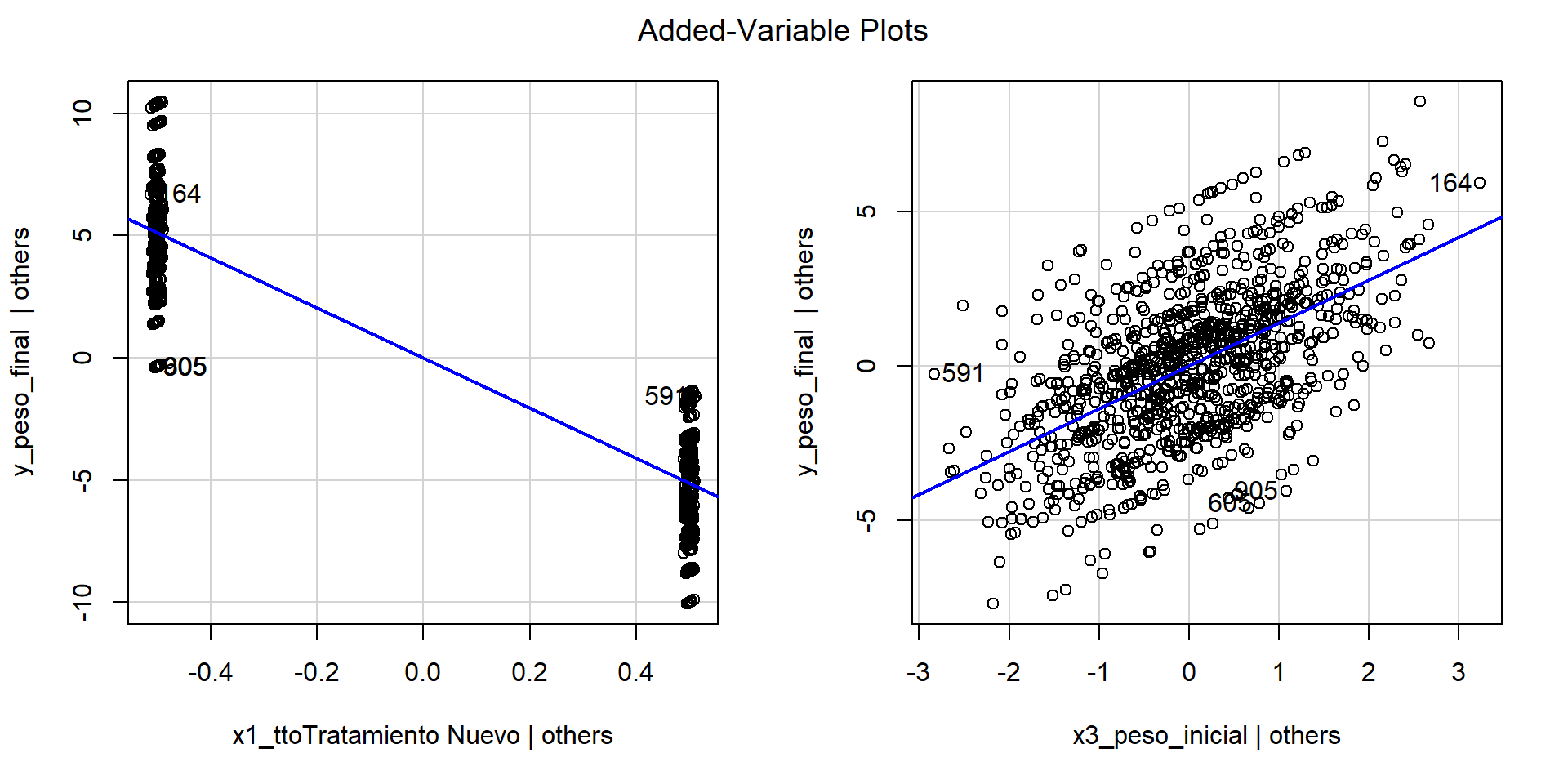
Linealidad con función termplot() de paquete {stats} (cont.)
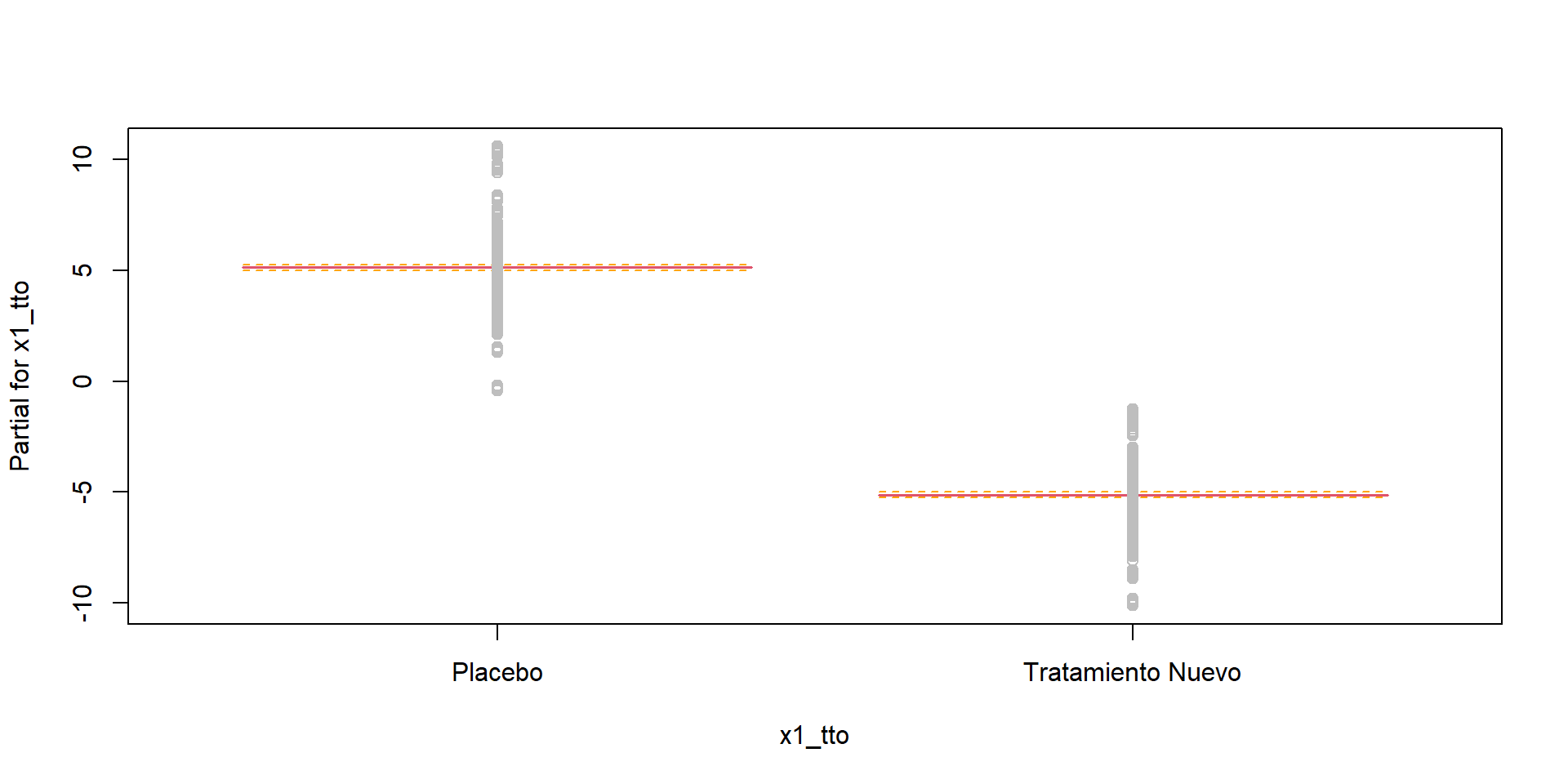
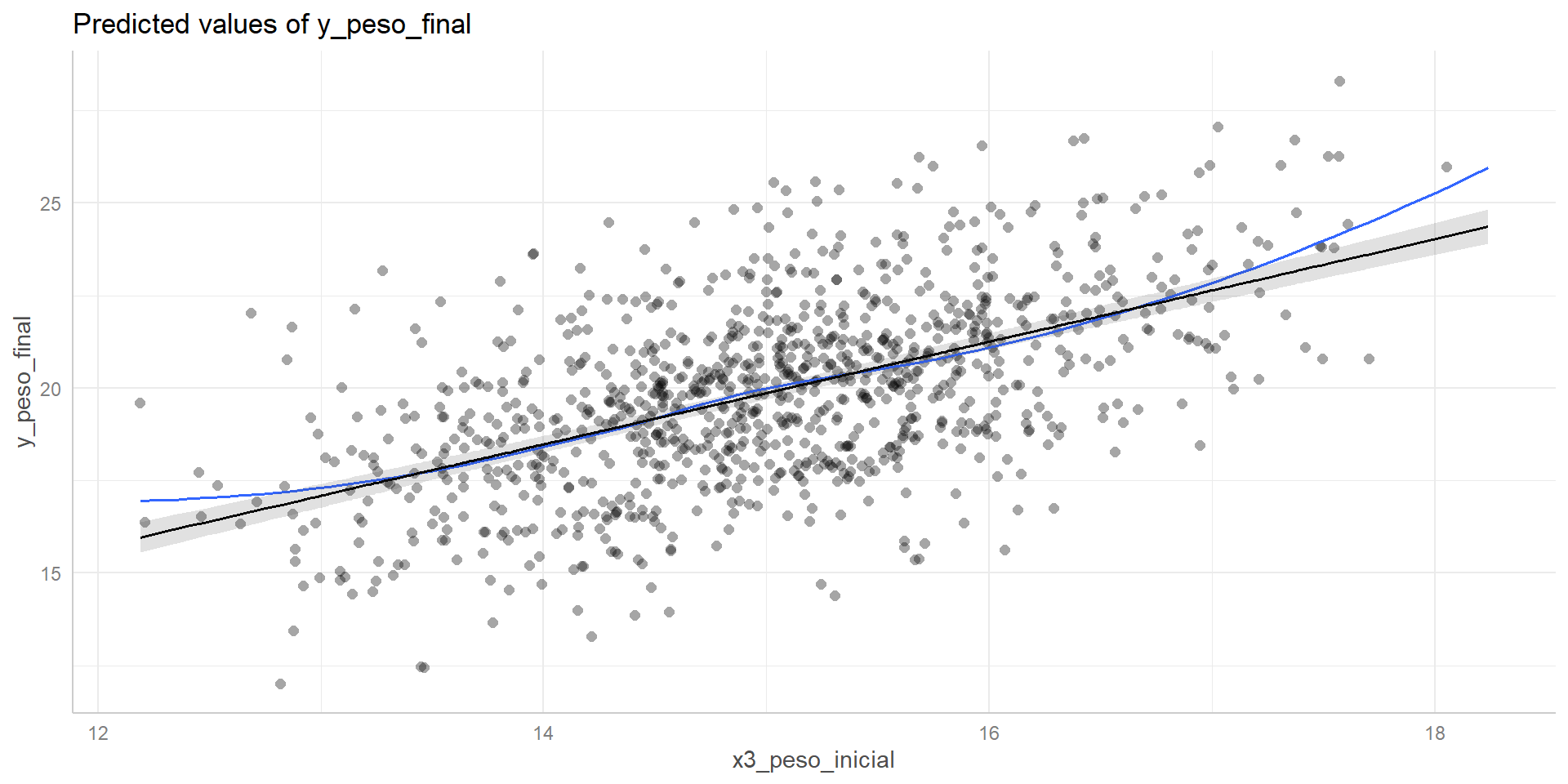
Linealidad con el paquete {ggeffects} (cont.)
Homogeneidad de varianzas (Homocedasticidad)
Se puede evaluar si la homocedasticidad es consistente según cada variable predictora.
Se sugiere usar
residuos estudentizados.
Test stat Pr(>|Test stat|)
x1_tto
x3_peso_inicial 1.2180 0.2235
Tukey test 0.5429 0.5872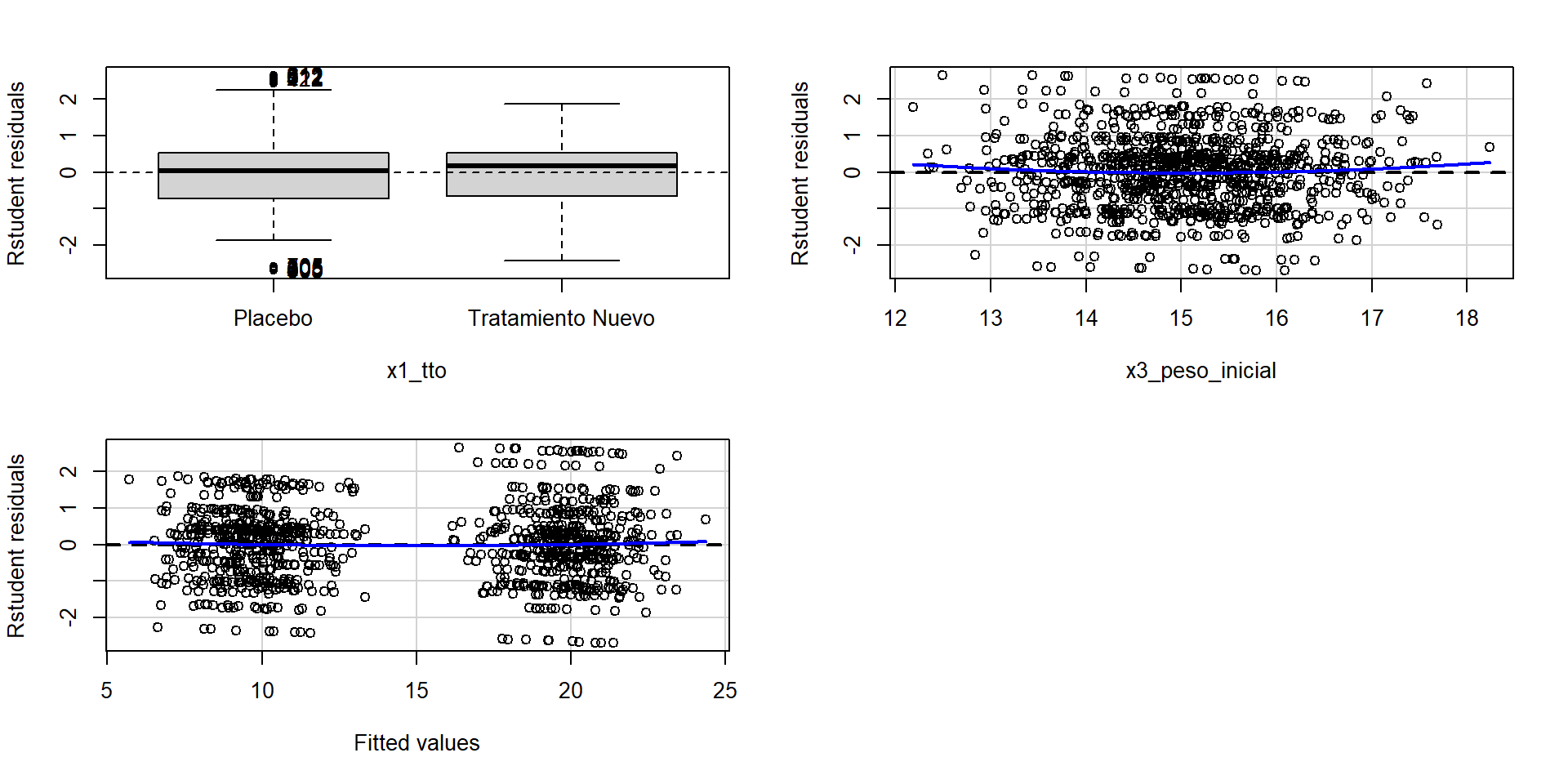
Homogeneidad de varianzas (Homocedasticidad)
Test stat Pr(>|Test stat|)
x1_tto
x3_peso_inicial 1.2180 0.2235
Tukey test 0.5429 0.5872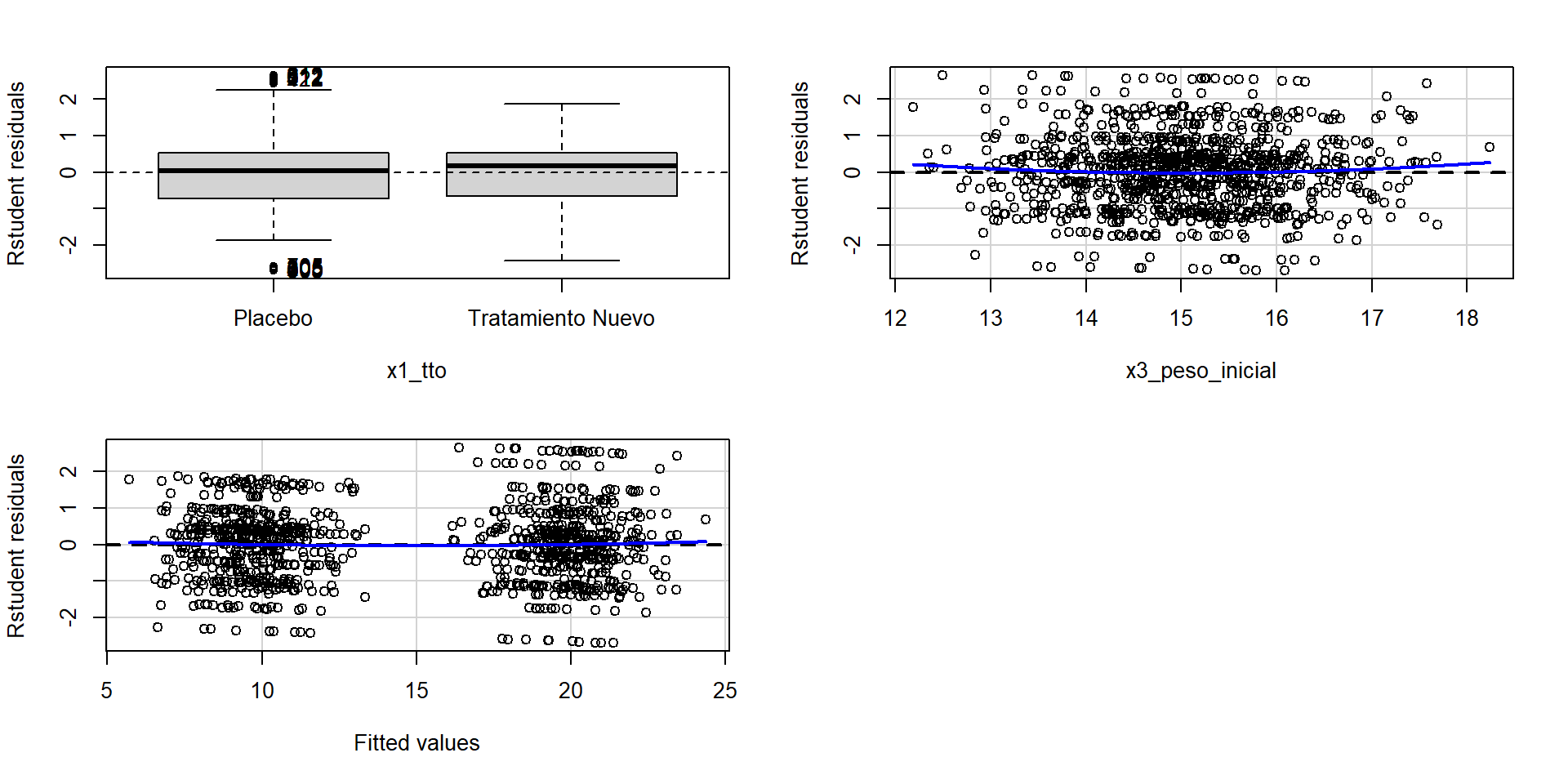
Outliers, puntos influyentes y dfbetas
Diversas medidas pueden usarse para detectar la existencia de valores extremos y puntos de alto apalancamiento que puedan ser influyentes.
La función influenceIndexPlot() del paquete {car} es muy útil para generar estos gráficos.
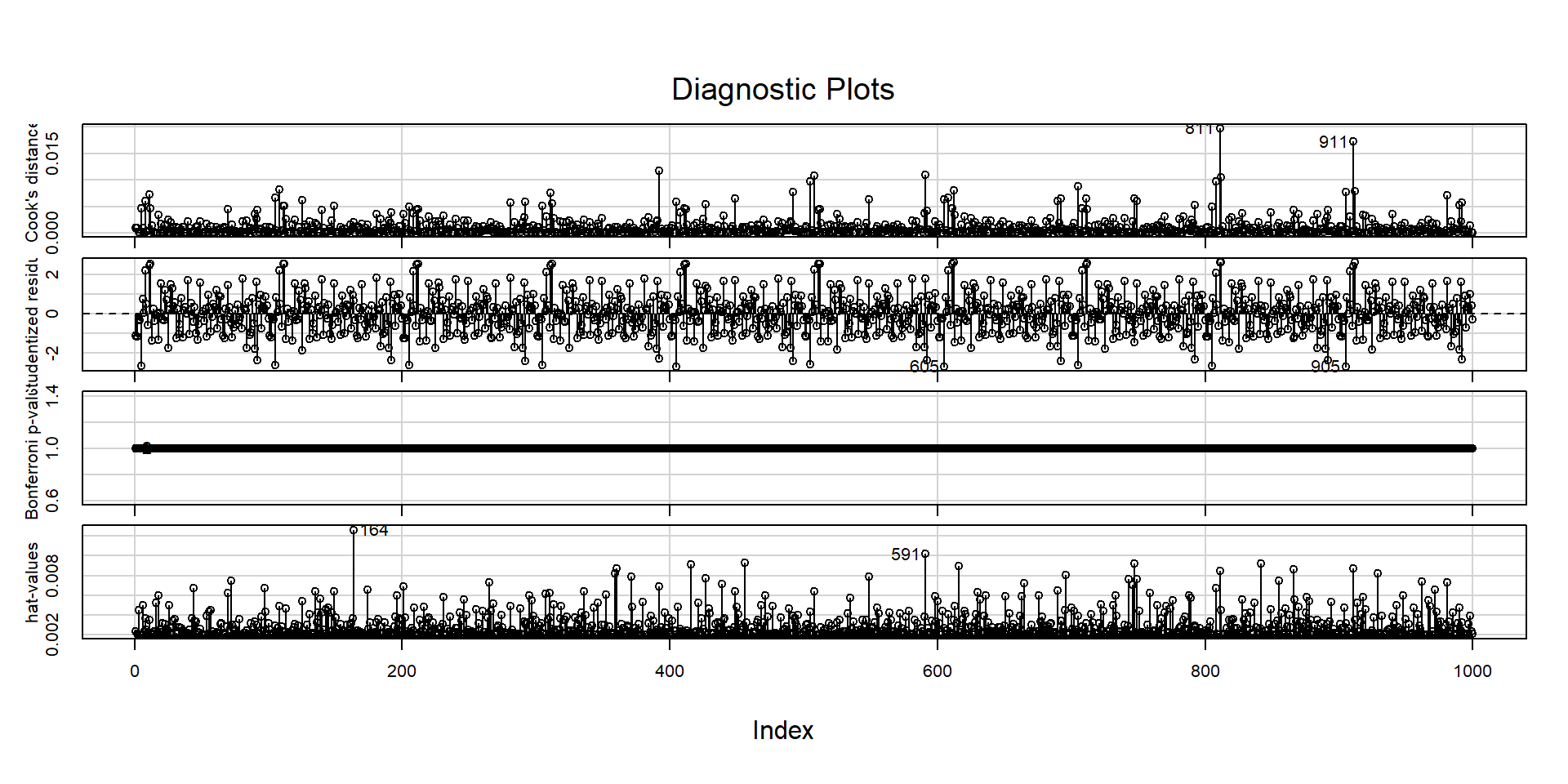
Outliers, puntos influyentes y dfbetas
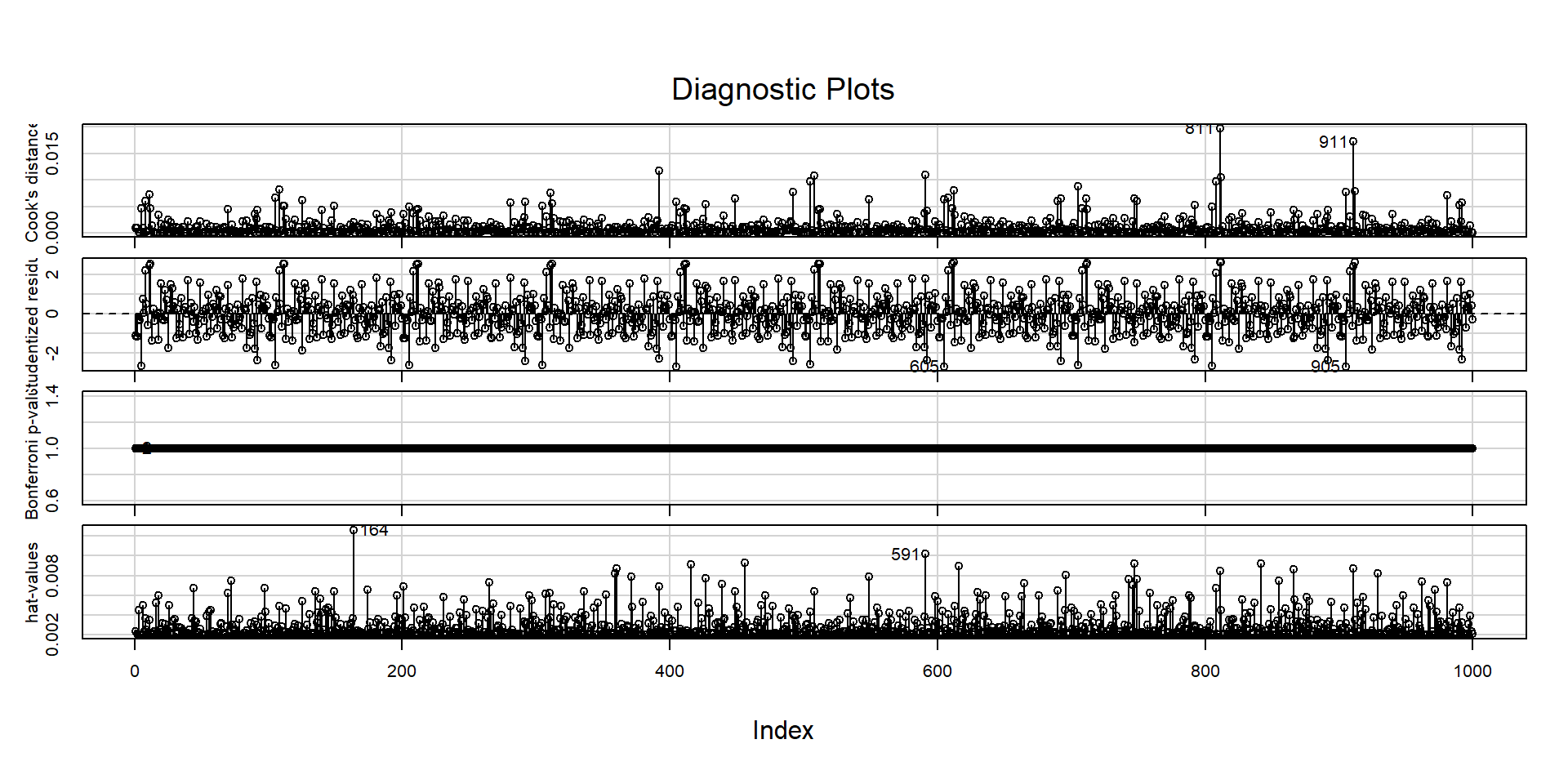
Outliers, puntos influyentes y dfbetas
En el caso de modelos explicativos, importa determinar si hay un impacto en los coeficientes de regresion.
Los
dfbetaspueden ser útiles para evaluar esto:
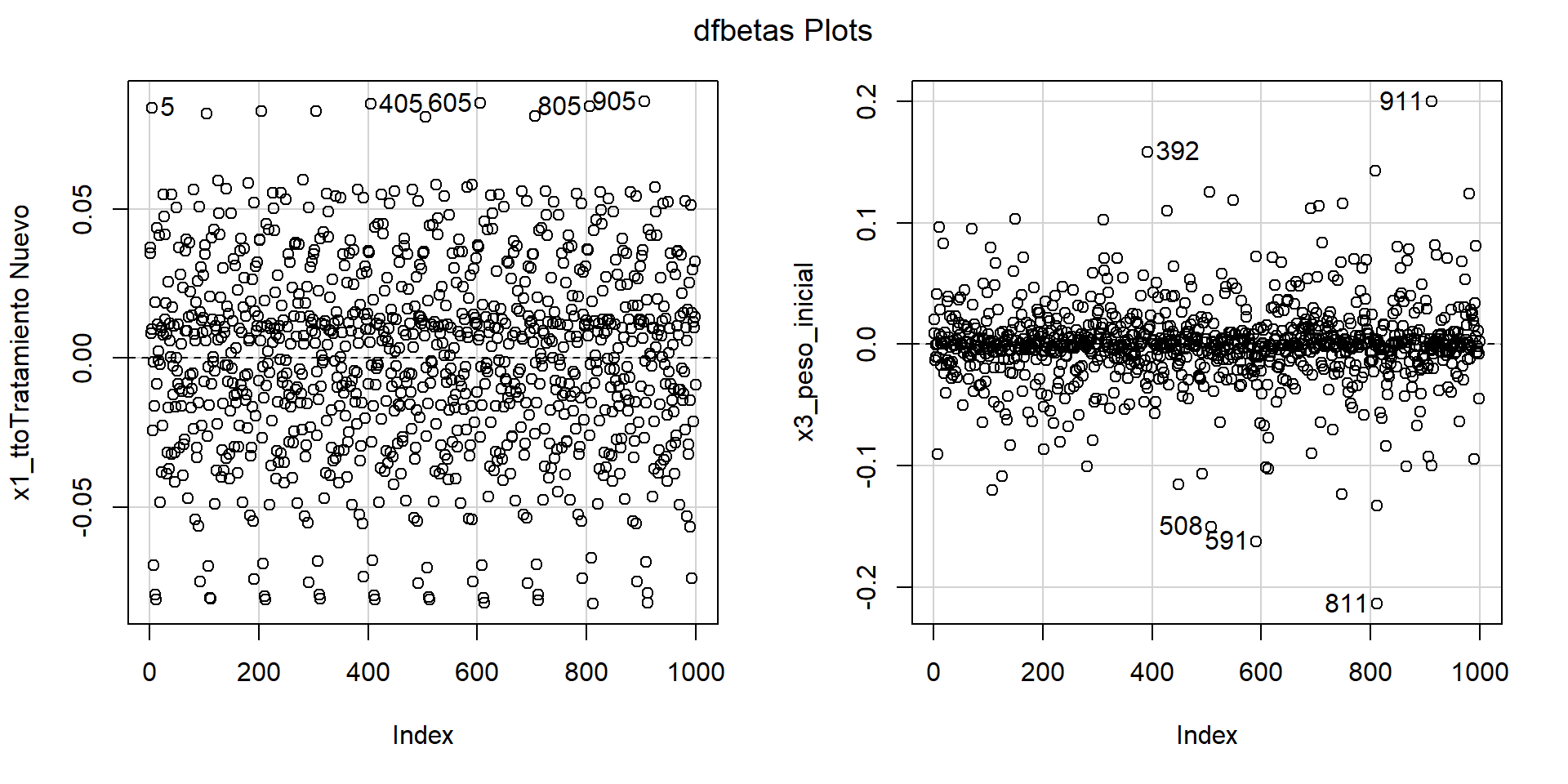
https://github.com/psotob91
percys1991@gmail.com