Sesión 9
Curso: R Aplicado a los Proyectos de Investigación
Percy Soto-Becerra, M.D., M.Sc(c)
InkaStats Data Science Solutions | Medical Branch
2022-10-21

Casos aplicado
- Identificar factores asociados a que el niño tenga alergia.
- Factores asociados al número de visitas médicas anuales.
- Especificación del modelo
Call:
glm(formula = docvis ~ female + age, family = poisson(link = "log"),
data = md_visit)
Deviance Residuals:
Min 1Q Median 3Q Max
-3.3562 -2.2285 -1.1346 0.3396 26.8860
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.0368083 0.0176597 -2.084 0.0371 *
female 0.3092910 0.0081168 38.105 <2e-16 ***
age 0.0227500 0.0003624 62.768 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for poisson family taken to be 1)
Null deviance: 122270 on 19608 degrees of freedom
Residual deviance: 116363 on 19606 degrees of freedom
AIC: 153636
Number of Fisher Scoring iterations: 6- Presentación con intervalos de confianza y exponenciada (OR):
female: El número medio de visitas anuales al médico en mujeres fue 20% veces más el de los hombres (RM = 1.33; IC95% 1.31 a 1.35; p < 0.001)age: Por cada incremento de la edad en un año, el número medio de visitas anuales al médico se incrementa en 1% (RM = 1.017; IC95% 1.016 a 1.018; p < 0.001).
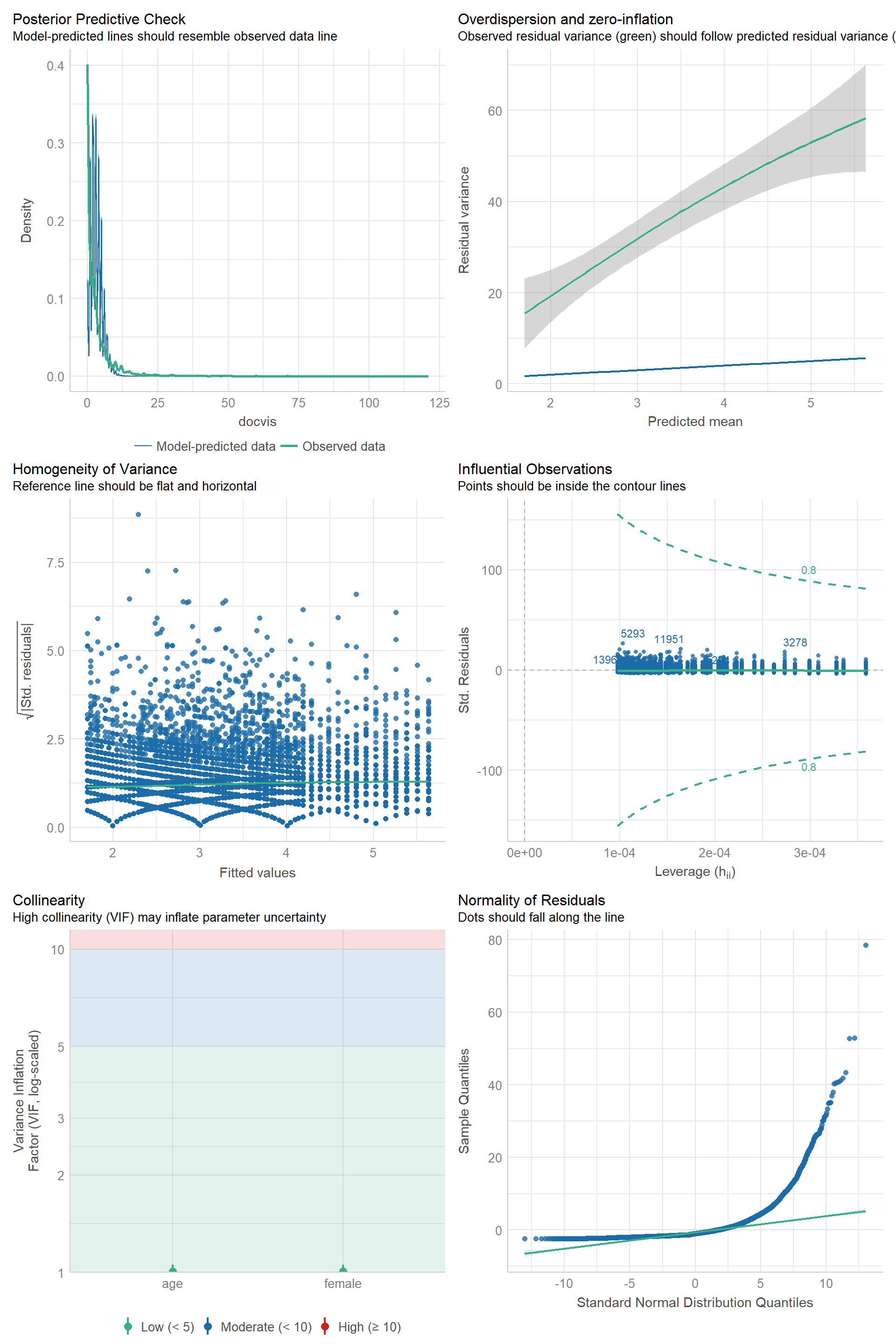
Linealidad del \(log(y_i)\) respecto a la combinación lineal de predictores.
Observaciones son independientes.
\(Y_i\) sigue distribución de Poisson.
- Supuesto de equivarianza.
No problemas de regresión:
No puntos influyentes
No colinealidad: Solo cuando esta es un problema.
Supuestos específicos si se busca generalizar a poblaciones conocidas, hacer inferencias causales o ambas.
Casos aplicado
- Identificar factores asociados a que el niño tenga alergia.
- Factores asociados al número de visitas médicas anuales.
- Especificación del modelo
Call:
glm.nb(formula = docvis ~ female + age, data = md_visit, init.theta = 0.4838144807,
link = log)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.5688 -1.3167 -0.4629 0.1127 6.5046
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.0366979 0.0457077 -0.803 0.422
female 0.3370406 0.0222361 15.157 <2e-16 ***
age 0.0224236 0.0009913 22.621 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for Negative Binomial(0.4838) family taken to be 1)
Null deviance: 21019 on 19608 degrees of freedom
Residual deviance: 20224 on 19606 degrees of freedom
AIC: 85857
Number of Fisher Scoring iterations: 1
Theta: 0.48381
Std. Err.: 0.00659
2 x log-likelihood: -85849.42400 - Presentación con intervalos de confianza y exponenciada (RM):
# A tibble: 3 × 7
term estimate std.error statistic p.value conf.low conf.high
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 0.964 0.0457 -0.803 4.22e- 1 0.882 1.05
2 female 1.40 0.0222 15.2 6.78e- 52 1.34 1.46
3 age 1.02 0.000991 22.6 2.72e-113 1.02 1.02female: El número medio de visitas anuales al médico en mujeres fue 20% veces más el de los hombres (RM = 1.40; IC95% 1.34 a 1.46; p < 0.001)age: Por cada incremento de la edad en un año, el número medio de visitas anuales al médico se incrementa en 2.3% (RM = 1.017; IC95% 1.021 a 1.025; p < 0.001).
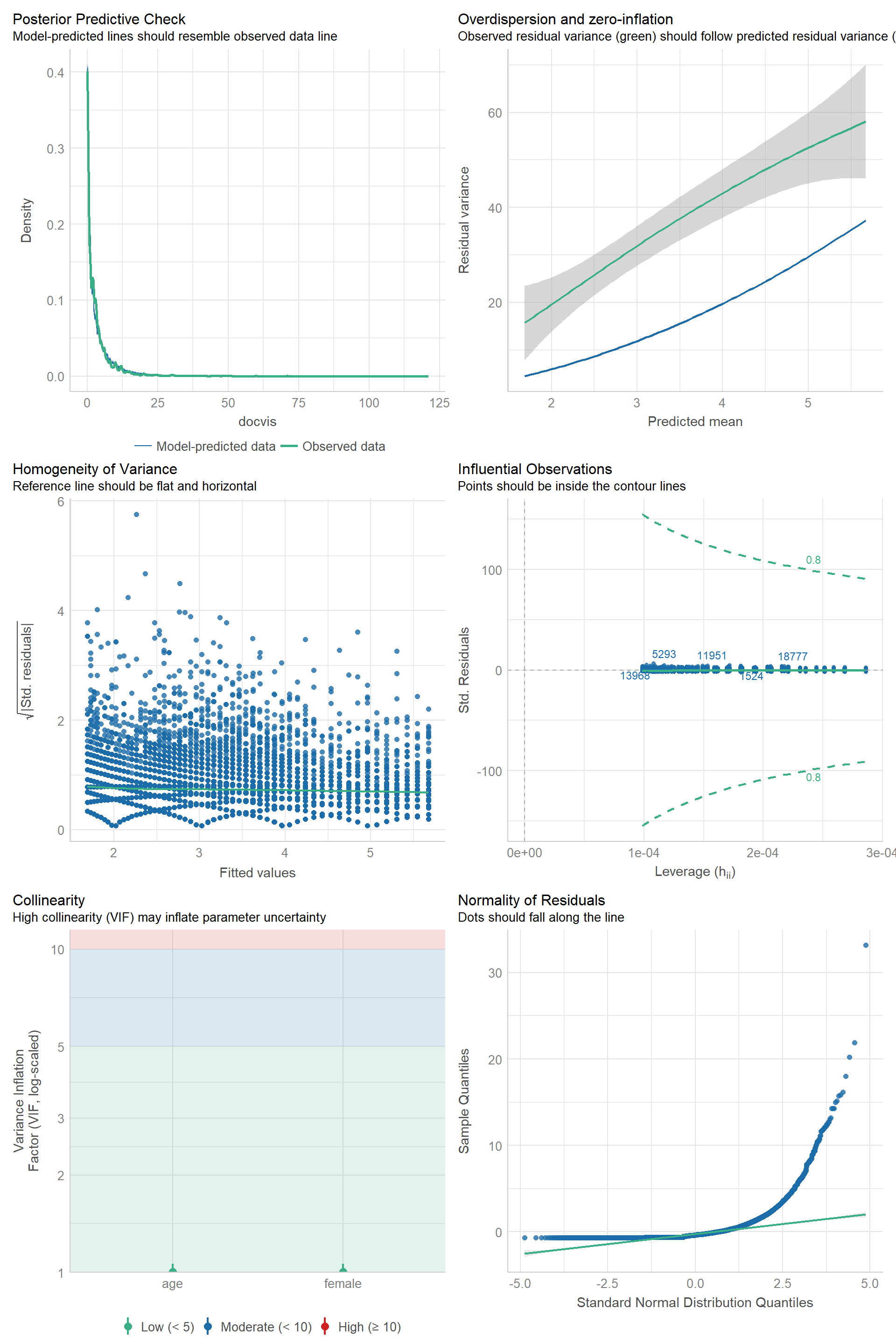
Linealidad del \(log(y_i)\) respecto a la combinación lineal de predictores.
Observaciones son independientes.
\(Y_i\) sigue distribución de Poisson.
- Supuesto de equivarianza.
No problemas de regresión:
No puntos influyentes
No colinealidad: Solo cuando esta es un problema.
Supuestos específicos si se busca generalizar a poblaciones conocidas, hacer inferencias causales o ambas.
https://github.com/psotob91
percys1991@gmail.com